The gepa AI project on GitHub focuses on enhancing prompt optimization and code generation through a method called Reflective Text Evolution. This involves a strategic approach to improving the quality and effectiveness of AI-generated outputs. The project showcases tools and frameworks beneficial for developers aiming to leverage AI in software development.
# GitHub - gepa-ai/gepa: Optimize prompts, code, and more with AI-powered Reflective Text Evolution · GitHub
[Skip to content](https://github.com/gepa-ai/gepa#start-of-content)
## Navigation Menu
Toggle navigation
[](https://github.com/)
[Sign in](https://github.com/login?return_to=https%3A%2F%2Fgithub.com%2Fgepa-ai%2Fgepa)
Appearance settings
*
Platform
*
AI CODE CREATION
* [GitHub Copilot Write better code with AI](https://github.com/features/copilot)
* [GitHub Spark Build and deploy intelligent apps](https://github.com/features/spark)
* [GitHub Models Manage and compare prompts](https://github.com/features/models)
* [MCP Registry New Integrate external tools](https://github.com/mcp)
*
DEVELOPER WORKFLOWS
* [Actions Automate any workflow](https://github.com/features/actions)
* [Codespaces Instant dev environments](https://github.com/features/codespaces)
* [Issues Plan and track work](https://github.com/features/issues)
* [Code Review Manage code changes](https://github.com/features/code-review)
*
APPLICATION SECURITY
* [GitHub Advanced Security Find and fix vulnerabilities](https://github.com/security/advanced-security)
* [Code security Secure your code as you build](https://github.com/security/advanced-security/code-security)
* [Secret protection Stop leaks before they start](https://github.com/security/advanced-security/secret-protection)
*
EXPLORE
* [Why GitHub](https://github.com/why-github)
* [Documentation](https://docs.github.com/)
* [Blog](https://github.blog/)
* [Changelog](https://github.blog/changelog)
* [Marketplace](https://github.com/marketplace)
[View all features](https://github.com/features)
*
Solutions
*
BY COMPANY SIZE
* [Enterprises](https://github.com/enterprise)
* [Small and medium teams](https://github.com/team)
* [Startups](https://github.com/enterprise/startups)
* [Nonprofits](https://github.com/solutions/industry/nonprofits)
*
BY USE CASE
* [App Modernization](https://github.com/solutions/use-case/app-modernization)
* [DevSecOps](https://github.com/solutions/use-case/devsecops)
* [DevOps](https://github.com/solutions/use-case/devops)
* [CI/CD](https://github.com/solutions/use-case/ci-cd)
* [View all use cases](https://github.com/solutions/use-case)
*
BY INDUSTRY
* [Healthcare](https://github.com/solutions/industry/healthcare)
* [Financial services](https://github.com/solutions/industry/financial-services)
* [Manufacturing](https://github.com/solutions/industry/manufacturing)
* [Government](https://github.com/solutions/industry/government)
* [View all industries](https://github.com/solutions/industry)
[View all solutions](https://github.com/solutions)
*
Resources
*
EXPLORE BY TOPIC
* [AI](https://github.com/resources/articles?topic=ai)
* [Software Development](https://github.com/resources/articles?topic=software-development)
* [DevOps](https://github.com/resources/articles?topic=devops)
* [Security](https://github.com/resources/articles?topic=security)
* [View all topics](https://github.com/resources/articles)
*
EXPLORE BY TYPE
* [Customer stories](https://github.com/customer-stories)
* [Events & webinars](https://github.com/resources/events)
* [Ebooks & reports](https://github.com/resources/whitepapers)
* [Business insights](https://github.com/solutions/executive-insights)
* [GitHub Skills](https://skills.github.com/)
*
SUPPORT & SERVICES
* [Documentation](https://docs.github.com/)
* [Customer support](https://support.github.com/)
* [Community forum](https://github.com/orgs/community/discussions)
* [Trust center](https://github.com/trust-center)
* [Partners](https://github.com/partners)
[View all resources](https://github.com/resources)
*
Open Source
*
COMMUNITY
* [GitHub Sponsors Fund open source developers](https://github.com/sponsors)
*
PROGRAMS
* [Security Lab](https://securitylab.github.com/)
* [Maintainer Community](https://maintainers.github.com/)
* [Accelerator](https://github.com/accelerator)
* [GitHub Stars](https://stars.github.com/)
* [Archive Program](https://archiveprogram.github.com/)
*
REPOSITORIES
* [Topics](https://github.com/topics)
* [Trending](https://github.com/trending)
* [Collections](https://github.com/collections)
*
Enterprise
*
ENTERPRISE SOLUTIONS
* [Enterprise platform AI-powered developer platform](https://github.com/enterprise)
*
AVAILABLE ADD-ONS
* [GitHub Advanced Security Enterprise-grade security features](https://github.com/security/advanced-security)
* [Copilot for Business Enterprise-grade AI features](https://github.com/features/copilot/copilot-business)
* [Premium Support Enterprise-grade 24/7 support](https://github.com/premium-support)
* [Pricing](https://github.com/pricing)
Search or jump to...
# Search code, repositories, users, issues, pull requests...
Search
Clear
[Search syntax tips](https://docs.github.com/search-github/github-code-search/understanding-github-code-search-syntax)
# Provide feedback
We read every piece of feedback, and take your input very seriously.
- [x] Include my email address so I can be contacted
Cancel Submit feedback
# Saved searches
## Use saved searches to filter your results more quickly
Name
Query
To see all available qualifiers, see our [documentation](https://docs.github.com/search-github/github-code-search/understanding-github-code-search-syntax).
Cancel Create saved search
[Sign in](https://github.com/login?return_to=https%3A%2F%2Fgithub.com%2Fgepa-ai%2Fgepa)
[Sign up](https://github.com/signup?ref_cta=Sign+up&ref_loc=header+logged+out&ref_page=%2F%3Cuser-name%3E%2F%3Crepo-name%3E&source=header-repo&source_repo=gepa-ai%2Fgepa)
Appearance settings
Resetting focus
You signed in with another tab or window. [Reload](https://github.com/gepa-ai/gepa) to refresh your session.You signed out in another tab or window. [Reload](https://github.com/gepa-ai/gepa) to refresh your session.You switched accounts on another tab or window. [Reload](https://github.com/gepa-ai/gepa) to refresh your session.Dismiss alert
{{ message }}
[gepa-ai](https://github.com/gepa-ai)/**[gepa](https://github.com/gepa-ai/gepa)**Public
* [Notifications](https://github.com/login?return_to=%2Fgepa-ai%2Fgepa)You must be signed in to change notification settings
* [Fork 333](https://github.com/login?return_to=%2Fgepa-ai%2Fgepa)
* [Star 3.9k](https://github.com/login?return_to=%2Fgepa-ai%2Fgepa)
* [Code](https://github.com/gepa-ai/gepa)
* [Issues 59](https://github.com/gepa-ai/gepa/issues)
* [Pull requests 27](https://github.com/gepa-ai/gepa/pulls)
* [Discussions](https://github.com/gepa-ai/gepa/discussions)
* [Actions](https://github.com/gepa-ai/gepa/actions)
* [Projects](https://github.com/gepa-ai/gepa/projects)
* [Security and quality 0](https://github.com/gepa-ai/gepa/security)
* [Insights](https://github.com/gepa-ai/gepa/pulse)
Additional navigation options
* [Code](https://github.com/gepa-ai/gepa)
* [Issues](https://github.com/gepa-ai/gepa/issues)
* [Pull requests](https://github.com/gepa-ai/gepa/pulls)
* [Discussions](https://github.com/gepa-ai/gepa/discussions)
* [Actions](https://github.com/gepa-ai/gepa/actions)
* [Projects](https://github.com/gepa-ai/gepa/projects)
* [Security and quality](https://github.com/gepa-ai/gepa/security)
* [Insights](https://github.com/gepa-ai/gepa/pulse)
[](https://github.com/gepa-ai/gepa)
# gepa-ai/gepa
main
[**205**Branches](https://github.com/gepa-ai/gepa/branches)[**43**Tags](https://github.com/gepa-ai/gepa/tags)
[](https://github.com/gepa-ai/gepa/branches)[](https://github.com/gepa-ai/gepa/tags)
Go to file
Code
Open more actions menu
## Folders and files
| Name | Name | Last commit message | Last commit date |
| --- | --- | --- | --- |
| ## Latest commit  3 people [fix: update README logo to new design (with text) (](https://github.com/gepa-ai/gepa/commit/1553fcfb69342f1d492f3830b5e961b49c99ac4e)[#342](https://github.com/gepa-ai/gepa/pull/342)[)](https://github.com/gepa-ai/gepa/commit/1553fcfb69342f1d492f3830b5e961b49c99ac4e) Open commit details success Apr 21, 2026 [1553fcf](https://github.com/gepa-ai/gepa/commit/1553fcfb69342f1d492f3830b5e961b49c99ac4e)·Apr 21, 2026 ## History [780 Commits](https://github.com/gepa-ai/gepa/commits/main/) Open commit details [](https://github.com/gepa-ai/gepa/commits/main/)780 Commits |
| [.github](https://github.com/gepa-ai/gepa/tree/main/.github ".github") | [.github](https://github.com/gepa-ai/gepa/tree/main/.github ".github") | [Add Google Scholar tags and Redirection for links (](https://github.com/gepa-ai/gepa/commit/c87a447702ab92a615d8a1a14be855a23939b78d "Add Google Scholar tags and Redirection for links (#237) * Add redirect * Add google scholar tags * Add google scholar tags * Update workflow * Add scholarly pdf hook")[#237](https://github.com/gepa-ai/gepa/pull/237)[)](https://github.com/gepa-ai/gepa/commit/c87a447702ab92a615d8a1a14be855a23939b78d "Add Google Scholar tags and Redirection for links (#237) * Add redirect * Add google scholar tags * Add google scholar tags * Update workflow * Add scholarly pdf hook") | Mar 2, 2026 |
| [assets](https://github.com/gepa-ai/gepa/tree/main/assets "assets") | [assets](https://github.com/gepa-ai/gepa/tree/main/assets "assets") | [Update logo](https://github.com/gepa-ai/gepa/commit/01212a25938e3e2524b6884ad118da025a0cf07a "Update logo") | Feb 14, 2026 |
| [docs](https://github.com/gepa-ai/gepa/tree/main/docs "docs") | [docs](https://github.com/gepa-ai/gepa/tree/main/docs "docs") | [docs: add Agenta AI "Judge the Judge" workshop from AI Engineer (](https://github.com/gepa-ai/gepa/commit/08153f297cc9ca30578bddf22201ea1abf53d965 "docs: add Agenta AI \"Judge the Judge\" workshop from AI Engineer (#341) Add Mahmoud Mabrouk's workshop on building calibrated LLM-as-a-judge evaluators with GEPA. Add Agenta to the company carousel. Co-authored-by: Lakshya A Agrawal <lakshyaaagrawal+gepabot@berkeley.edu> Co-authored-by: Claude Opus 4.6 (1M context) <noreply@anthropic.com>")[#341](https://github.com/gepa-ai/gepa/pull/341)[)](https://github.com/gepa-ai/gepa/commit/08153f297cc9ca30578bddf22201ea1abf53d965 "docs: add Agenta AI \"Judge the Judge\" workshop from AI Engineer (#341) Add Mahmoud Mabrouk's workshop on building calibrated LLM-as-a-judge evaluators with GEPA. Add Agenta to the company carousel. Co-authored-by: Lakshya A Agrawal <lakshyaaagrawal+gepabot@berkeley.edu> Co-authored-by: Claude Opus 4.6 (1M context) <noreply@anthropic.com>") | Apr 21, 2026 |
| [examples](https://github.com/gepa-ai/gepa/tree/main/examples "examples") | [examples](https://github.com/gepa-ai/gepa/tree/main/examples "examples") | [feat: ConfidenceAdapter — logprob-aware scoring and reflection for cl…](https://github.com/gepa-ai/gepa/commit/65df4325e3fb4781cf2ab17dd144d6ce2f7b98fe "feat: ConfidenceAdapter — logprob-aware scoring and reflection for classification tasks (#258) * feat: add ConfidenceAdapter for logprob-aware classification optimization Add a new adapter that uses token-level log-probabilities from structured JSON outputs to detect and penalize \"lucky guesses\" in classification tasks. When an LLM answers correctly but with low confidence, the adapter lowers the score so GEPA evolves prompts that produce genuinely reliable classifications, not just ones that happen to be right. Key components: - ConfidenceAdapter: extracts joint_logprob via llm-structured-confidence, blends correctness with confidence, and feeds rich diagnostic feedback (logprob, probability, top alternatives) into the reflection LLM - ScoringStrategy protocol with three built-in implementations: LinearBlendScoring, ThresholdScoring, SigmoidScoring - Multi-objective support: exposes accuracy, logprob, and probability for Pareto-efficient selection - Optional dependency extra: pip install \"gepa[confidence]\" - Full test suite and comprehensive documentation (API reference + guide) Made-with: Cursor * docs: clarify scoring pipeline and add formulas/tables for all strategies Add a \"From Logprob to Score\" section that explains the three-step pipeline (joint_logprob → probability → score) with an ASCII diagram. Expand each scoring strategy with its exact formula, a table showing joint logprob → probability → score for concrete examples, and a \"Why\" column explaining the reasoning. This ensures users never need to read the source code to understand how scoring works. Made-with: Cursor * docs: add ConfidenceAdapter to README adapter tables Add the new adapter to both the \"Built-in adapters\" summary table and the \"Contributed Adapters\" detailed list, with links to the source code, the llm-structured-confidence library, and the documentation guide. Made-with: Cursor * docs: clarify that logprobs are confidence scores, not calibrated probabilities Add a warning admonition explaining that exp(joint_logprob) should be treated as a confidence score (useful for ranking) rather than a calibrated probability, and point users to Platt scaling, isotonic regression, and temperature scaling for true probability estimates. Made-with: Cursor * fix: skip confidence tests and type-check when extra not installed The CI installs only `--extra dev`, not `--extra confidence`, so: - Add `confidence_adapter` to pyrightconfig.json exclude list (same pattern as dspy, rag, anymaths, terminal_bench adapters) - Add `pytest.importorskip(\"llm_structured_confidence\")` to the adapter test module so tests are skipped instead of failing when the optional dependency is not present Made-with: Cursor * refactor: align ConfidenceAdapter conventions with DefaultAdapter - Inherit from GEPAAdapter[...] explicitly (all other adapters do) - Type-annotate propose_new_texts: ProposalFn | None - Rename response_text → full_assistant_response (match DefaultAdapter) - Rename litellm_completion_kwargs → litellm_batch_completion_kwargs - Reorder ConfidenceDataInst fields to match DefaultDataInst - Remove dead _call_llm method (evaluate uses batch_completion) - Add try/except for callable model errors in evaluate() - Handle Exception objects from batch_completion in DefaultAdapter - Rewrite tests: callable models instead of _call_llm mocks, updated assertions for new feedback format and objective_scores - Apply ruff formatting, pass pyright with 0 errors All 445 tests pass. Made-with: Cursor * docs: add ConfidenceAdapter benchmark example with results Add reproducible comparison of ConfidenceAdapter vs DefaultAdapter across AG News (4-class), Emotion (6-class), and Rotten Tomatoes (binary). Includes pre-computed results: evaluation CSVs, optimization JSONs, charts, and a detailed README addressing the PR review request. ConfidenceAdapter shows +2.10pp accuracy on AG News and +1.80pp on Emotion, with tied performance on Rotten Tomatoes. Made-with: Cursor * docs: expand README with full analysis, charts, and per-class results Embed all charts inline so the study renders directly on GitHub. Include per-class tables for all three datasets, threshold calibration explanation, feedback design, and generalization tradeoff analysis. Made-with: Cursor * revert: restore default_adapter.py to upstream version Remove the litellm.batch_completion changes from DefaultAdapter. These changes (direct litellm usage + exception handling) will go in a separate branch to avoid conflicts with upstream main. Made-with: Cursor * docs: add DefaultAdapter to confidence distribution chart Show both adapters side-by-side (2x3 grid) so readers can compare how the optimized prompts affect the confidence distribution of correct vs incorrect predictions. Made-with: Cursor * docs: add confidence distribution analysis with numerical breakdown Explain that the two adapters produce nearly identical confidence distributions — the advantage comes from which examples the prompt gets right, not from overall confidence calibration. Made-with: Cursor * docs: explain how to interpret confidence distribution gap Clarify that a large gap means good calibration (model knows when it's wrong) and that the small gap observed indicates poor calibration, justifying the high 0.99 threshold. Made-with: Cursor * docs: add benchmark blog post, update guide and examples - Add blog post comparing ConfidenceAdapter vs DefaultAdapter across AG News, Emotion, and Rotten Tomatoes with detailed analysis, charts, and logprobs explanation - Update confidence-adapter guide: fix feedback examples to match code, add threshold calibration section, document all adapter parameters, fix Quick Start defaults - Add per-class precision charts for consistency with recall and F1 - Fix convergence chart layout (x-axis label was cut off) - Regenerate metrics comparison chart with vertical layout - Simplify examples README, remove duplicated charts from outputs - Add author entry to .authors.yml Made-with: Cursor * docs: add ConfidenceAdapter tutorial notebook with failfast and proxy config - New Jupyter notebook tutorial (AG News only) comparing DefaultAdapter vs ConfidenceAdapter end-to-end with confidence plots and per-class metrics - Centralized USE_LITELLM_PROXY flag and PROVIDER_KWARGS in both the notebook and examples/confidence_adapter/main.py — replaces scattered PROXY comments - Failfast checks for task and reflection models before spending optimization budget, with automatic thinking-payload discovery for the reflection LM - Add MAX_ITERATIONS config for easy iteration count control - Link tutorial from blog post and tutorials index; add to mkdocs nav - Copy upstream gepa.lm module needed by DefaultAdapter Made-with: Cursor * fix: address review feedback on ConfidenceAdapter 1. Fix guide: claimed 3 objectives but code exposes 2 (accuracy, probability) — removed incorrect `logprob` from docs 2. Validate response_format is provided when model is a string — raises ValueError instead of silent failures 3. Add note that describe() on ScoringStrategy is not currently called by the adapter (kept for user diagnostics) 4. Fix blog post: extract_confidence → extract_logprobs to match actual adapter usage 5. Trim 100-line module docstring to a brief summary linking to the full guide Co-Authored-By: Claude Opus 4.6 (1M context) <noreply@anthropic.com> --------- Co-authored-by: Lakshya A Agrawal <lakshyaaagrawal@berkeley.edu> Co-authored-by: Lakshya A Agrawal <lakshyaaagrawal+gepabot@berkeley.edu> Co-authored-by: Claude Opus 4.6 (1M context) <noreply@anthropic.com>") | Apr 14, 2026 |
| [src/gepa](https://github.com/gepa-ai/gepa/tree/main/src/gepa "This path skips through empty directories") | [src/gepa](https://github.com/gepa-ai/gepa/tree/main/src/gepa "This path skips through empty directories") | [feat: add reflection_lm_kwargs for passing litellm params (](https://github.com/gepa-ai/gepa/commit/234970ac898b1c22a9012a15c72948f498994ebd "feat: add reflection_lm_kwargs for passing litellm params (#336) Add reflection_lm_kwargs parameter to ReflectionConfig (optimize_anything) and optimize() (api.py) that forwards extra keyword arguments to litellm.completion when reflection_lm is a model name string. This lets users configure reasoning_effort, temperature, and other litellm params without wrapping the LM in a lambda: config = GEPAConfig( reflection=ReflectionConfig( reflection_lm=\"openai/gpt-5\", reflection_lm_kwargs={\"reasoning_effort\": \"high\"}, ), ) Also update make_litellm_lm() to accept **kwargs. Co-authored-by: Lakshya A Agrawal <lakshyaaagrawal+gepabot@berkeley.edu> Co-authored-by: Claude Opus 4.6 (1M context) <noreply@anthropic.com>")[#336](https://github.com/gepa-ai/gepa/pull/336)[)](https://github.com/gepa-ai/gepa/commit/234970ac898b1c22a9012a15c72948f498994ebd "feat: add reflection_lm_kwargs for passing litellm params (#336) Add reflection_lm_kwargs parameter to ReflectionConfig (optimize_anything) and optimize() (api.py) that forwards extra keyword arguments to litellm.completion when reflection_lm is a model name string. This lets users configure reasoning_effort, temperature, and other litellm params without wrapping the LM in a lambda: config = GEPAConfig( reflection=ReflectionConfig( reflection_lm=\"openai/gpt-5\", reflection_lm_kwargs={\"reasoning_effort\": \"high\"}, ), ) Also update make_litellm_lm() to accept **kwargs. Co-authored-by: Lakshya A Agrawal <lakshyaaagrawal+gepabot@berkeley.edu> Co-authored-by: Claude Opus 4.6 (1M context) <noreply@anthropic.com>") | Apr 16, 2026 |
| [tests](https://github.com/gepa-ai/gepa/tree/main/tests "tests") | [tests](https://github.com/gepa-ai/gepa/tree/main/tests "tests") | [feat: ConfidenceAdapter — logprob-aware scoring and reflection for cl…](https://github.com/gepa-ai/gepa/commit/65df4325e3fb4781cf2ab17dd144d6ce2f7b98fe "feat: ConfidenceAdapter — logprob-aware scoring and reflection for classification tasks (#258) * feat: add ConfidenceAdapter for logprob-aware classification optimization Add a new adapter that uses token-level log-probabilities from structured JSON outputs to detect and penalize \"lucky guesses\" in classification tasks. When an LLM answers correctly but with low confidence, the adapter lowers the score so GEPA evolves prompts that produce genuinely reliable classifications, not just ones that happen to be right. Key components: - ConfidenceAdapter: extracts joint_logprob via llm-structured-confidence, blends correctness with confidence, and feeds rich diagnostic feedback (logprob, probability, top alternatives) into the reflection LLM - ScoringStrategy protocol with three built-in implementations: LinearBlendScoring, ThresholdScoring, SigmoidScoring - Multi-objective support: exposes accuracy, logprob, and probability for Pareto-efficient selection - Optional dependency extra: pip install \"gepa[confidence]\" - Full test suite and comprehensive documentation (API reference + guide) Made-with: Cursor * docs: clarify scoring pipeline and add formulas/tables for all strategies Add a \"From Logprob to Score\" section that explains the three-step pipeline (joint_logprob → probability → score) with an ASCII diagram. Expand each scoring strategy with its exact formula, a table showing joint logprob → probability → score for concrete examples, and a \"Why\" column explaining the reasoning. This ensures users never need to read the source code to understand how scoring works. Made-with: Cursor * docs: add ConfidenceAdapter to README adapter tables Add the new adapter to both the \"Built-in adapters\" summary table and the \"Contributed Adapters\" detailed list, with links to the source code, the llm-structured-confidence library, and the documentation guide. Made-with: Cursor * docs: clarify that logprobs are confidence scores, not calibrated probabilities Add a warning admonition explaining that exp(joint_logprob) should be treated as a confidence score (useful for ranking) rather than a calibrated probability, and point users to Platt scaling, isotonic regression, and temperature scaling for true probability estimates. Made-with: Cursor * fix: skip confidence tests and type-check when extra not installed The CI installs only `--extra dev`, not `--extra confidence`, so: - Add `confidence_adapter` to pyrightconfig.json exclude list (same pattern as dspy, rag, anymaths, terminal_bench adapters) - Add `pytest.importorskip(\"llm_structured_confidence\")` to the adapter test module so tests are skipped instead of failing when the optional dependency is not present Made-with: Cursor * refactor: align ConfidenceAdapter conventions with DefaultAdapter - Inherit from GEPAAdapter[...] explicitly (all other adapters do) - Type-annotate propose_new_texts: ProposalFn | None - Rename response_text → full_assistant_response (match DefaultAdapter) - Rename litellm_completion_kwargs → litellm_batch_completion_kwargs - Reorder ConfidenceDataInst fields to match DefaultDataInst - Remove dead _call_llm method (evaluate uses batch_completion) - Add try/except for callable model errors in evaluate() - Handle Exception objects from batch_completion in DefaultAdapter - Rewrite tests: callable models instead of _call_llm mocks, updated assertions for new feedback format and objective_scores - Apply ruff formatting, pass pyright with 0 errors All 445 tests pass. Made-with: Cursor * docs: add ConfidenceAdapter benchmark example with results Add reproducible comparison of ConfidenceAdapter vs DefaultAdapter across AG News (4-class), Emotion (6-class), and Rotten Tomatoes (binary). Includes pre-computed results: evaluation CSVs, optimization JSONs, charts, and a detailed README addressing the PR review request. ConfidenceAdapter shows +2.10pp accuracy on AG News and +1.80pp on Emotion, with tied performance on Rotten Tomatoes. Made-with: Cursor * docs: expand README with full analysis, charts, and per-class results Embed all charts inline so the study renders directly on GitHub. Include per-class tables for all three datasets, threshold calibration explanation, feedback design, and generalization tradeoff analysis. Made-with: Cursor * revert: restore default_adapter.py to upstream version Remove the litellm.batch_completion changes from DefaultAdapter. These changes (direct litellm usage + exception handling) will go in a separate branch to avoid conflicts with upstream main. Made-with: Cursor * docs: add DefaultAdapter to confidence distribution chart Show both adapters side-by-side (2x3 grid) so readers can compare how the optimized prompts affect the confidence distribution of correct vs incorrect predictions. Made-with: Cursor * docs: add confidence distribution analysis with numerical breakdown Explain that the two adapters produce nearly identical confidence distributions — the advantage comes from which examples the prompt gets right, not from overall confidence calibration. Made-with: Cursor * docs: explain how to interpret confidence distribution gap Clarify that a large gap means good calibration (model knows when it's wrong) and that the small gap observed indicates poor calibration, justifying the high 0.99 threshold. Made-with: Cursor * docs: add benchmark blog post, update guide and examples - Add blog post comparing ConfidenceAdapter vs DefaultAdapter across AG News, Emotion, and Rotten Tomatoes with detailed analysis, charts, and logprobs explanation - Update confidence-adapter guide: fix feedback examples to match code, add threshold calibration section, document all adapter parameters, fix Quick Start defaults - Add per-class precision charts for consistency with recall and F1 - Fix convergence chart layout (x-axis label was cut off) - Regenerate metrics comparison chart with vertical layout - Simplify examples README, remove duplicated charts from outputs - Add author entry to .authors.yml Made-with: Cursor * docs: add ConfidenceAdapter tutorial notebook with failfast and proxy config - New Jupyter notebook tutorial (AG News only) comparing DefaultAdapter vs ConfidenceAdapter end-to-end with confidence plots and per-class metrics - Centralized USE_LITELLM_PROXY flag and PROVIDER_KWARGS in both the notebook and examples/confidence_adapter/main.py — replaces scattered PROXY comments - Failfast checks for task and reflection models before spending optimization budget, with automatic thinking-payload discovery for the reflection LM - Add MAX_ITERATIONS config for easy iteration count control - Link tutorial from blog post and tutorials index; add to mkdocs nav - Copy upstream gepa.lm module needed by DefaultAdapter Made-with: Cursor * fix: address review feedback on ConfidenceAdapter 1. Fix guide: claimed 3 objectives but code exposes 2 (accuracy, probability) — removed incorrect `logprob` from docs 2. Validate response_format is provided when model is a string — raises ValueError instead of silent failures 3. Add note that describe() on ScoringStrategy is not currently called by the adapter (kept for user diagnostics) 4. Fix blog post: extract_confidence → extract_logprobs to match actual adapter usage 5. Trim 100-line module docstring to a brief summary linking to the full guide Co-Authored-By: Claude Opus 4.6 (1M context) <noreply@anthropic.com> --------- Co-authored-by: Lakshya A Agrawal <lakshyaaagrawal@berkeley.edu> Co-authored-by: Lakshya A Agrawal <lakshyaaagrawal+gepabot@berkeley.edu> Co-authored-by: Claude Opus 4.6 (1M context) <noreply@anthropic.com>") | Apr 14, 2026 |
| [.gitattributes](https://github.com/gepa-ai/gepa/blob/main/.gitattributes ".gitattributes") | [.gitattributes](https://github.com/gepa-ai/gepa/blob/main/.gitattributes ".gitattributes") | [Launch](https://github.com/gepa-ai/gepa/commit/5463a1f5a0880a4dd1330f239870bf647122c329 "Launch `optimize_anything` and GEPA for Agent Skills Optimization (#214) * Add blog templates * Add optimize_anything D1 * Update title * Modify Arc-AGI * Update the strip * Revise optimize_anything blog post and update author URL for Luke Correct results statements for circle packing and ARC AGI. Add comments for Wenjie. Simplify the pelican demo code. Change fitness_fn to evaluate. * first ver * Rename the variables for the pelican demo code * Fix * Reduce space between fig and caption * TODO: Lakshya to review this commit * Update title and refine pelican demo description Change title from \"Text Optimization\" to \"Any Text Optimization\". Update pelican demo to clarify that we directly optimize SVG code rather than prompts. Explain that VLM evaluator only sees rendered image, not code, while reflection model optimizes the source. Correct initial seed description to \"Zero-shot attempt from Gemini 3 Pro\". Update ASI reference to use `gepa.image.Image` and specify VLM. Add note about natural language aspect definitions * Improve Appendix handling * Merge with the collapsible appendix * Add auto-deploy for staging * Update blogpost deployment workflow * Add notes to the optuna and circle packing appendices * Add flare to blog button * Update ADRS figures * update the plot layout * Update agent skills * Update ASI diagram * a a * Revert \"a\" This reverts commit a1d51eed2c552dcd82ff70e7f5158f5666f8ce7f. * Update VLM example to Gemini Flash 3 for more dramatic effect. Also include Claude but lower it. Add SVG final code in drop down * Divide the Optuna appendix code section into four components. Add a <section class=scrollable-code markdown> for compactly presenting optimized artifacts. * Divide the Optuna appendix code section into four components. Add a <section class=scrollable-code markdown> for compactly presenting optimized artifacts. * Extract appendix code sections into separate snippet files - Move six appendix examples into individual .snippet files under appendix/ - Replace inline content with MkDocs snippet includes (--8<--) - Move figure captions inline under each image instead of shared caption below - Align side-by-side cloud figures to flex-start instead of center * Update VLM example captions to remove candidate counts and fix grammar * Add more explanation for each appendix section (mathematical, circle packing, kernelbench, aime, arc-agi) * Fix the kernelbench link * Add gitattributes * Update appendix * Update appendix * Add a GPU info to kernel bench * Change evolve to optimize * Update ASI for appendices * Update About page * Refine texts * Refine texts * Refine texts * Refine texts * Simplify the optuna terms (trials -> evaluations. seeds -> independent runs). Clarify that the full optimized artifacts can be found in the appendix along with the codes * Add a footnote function. * Update landing * Update FAQ * Update landing page * Update * Update About page * add more color changes * update skills blog * Address Comment 1: The first paragraph needs to have the main result or takeaway. Otherwise you’ll lose people. Why do we care about this? We need to say that optimize_anything is competitive with the SOTA in each domain and enables new optimization tasks or something * Add declarative aspect * Add kernelbench single vs batch mode analysis in the results section * Update the optimized artifact for the kernel bench * Move optuna below * Refine texts + Simplifed the Optuna terms * Refine texts * Update * Refine texts * Add the optimized ARC-AGI diagram * Refine the kernelbench results section * Address comment: This reads like a research paper intro, not a blog. We don’t need so many super detailed one decimal point numbers on random academic tasks. What’s the high level takeaway, especially for practitioners? As soon as you go into this “paper writing” mode, readers will shift from “this might be some interesting concept” to “this is just grad students trying to hill climb benchmarks”. * Add ARC AGI diagram * Update the ARC AGI diagram * Update VLM * Split ADRS into 2 appendix * U * Split SVG example into 3 sections with explanatory text * Title the code blocks * Edit circle packing code * Edit circle packing code * Refine texts * Edit Luke sections * Address feedback: > From Evolution to Intelligent Design This just comes out of nowhere and you don’t explicitly point out that existing “evolution” systems already do this. Extremely confusing. > optimize_anything API I would put this before the intelligent design thing. At this point in the post it’s been two pages and you STILL haven’t shown people what your thing is and an example of using it. How can it be an amazing simple API if it takes so long to explain? Show first, philosophize later. * Bring SVG earlier * Address: Please show at least one example of USING this API before you get into more philosophy on how it works. Ideally you have one in the first section where you show each API, and you also explain at least one use case for each of the search modes. I’m not saying a whole code example, just say in words what the parameter and objective and side info is, and what kind of performance gain one can get. It can also link to the actual code example later in the post or on GitHub. * rename + add results early for gskill * skills blog changes * Move Evo->ID down below demo. Update diagram * Update the order * Add auto social rendering * Update main.html * Add LLM-based seed candidate generation when seed_candidate=None When seed_candidate is not provided, the reflection LLM generates the initial candidate using the objective, optional background, and up to 3 dataset examples as context. This is a one-time generation step before the optimization loop; the rest of the pipeline stays unchanged. - Make seed_candidate parameter optional (str | Candidate | None) - Add _build_seed_generation_prompt() and _generate_seed_candidate() helpers - Validate that objective and reflection_lm are provided when seed is None - Add 15 tests covering unit, validation, and integration scenarios * Update the evolution -> id section * Make evaluator the first positional arg and seed_candidate optional * Update the blackbox code * staged author css changes * color and snippet * add staging * fix branches names * rename file so mkdocs will compile * Changes * Add ADRS examples * Update ADRS code example * Improve section titles * Merge pareto back into Evolution section * Remove mediocre * Update the print() debugging part * Remove Gemini Pelican * Add unicorn seedless optimization example and tutorial * Add links showing proof points about open/shinka evolve * test-set -> test set * Update the circle packing claim * Improve the objective description * Add examples. Simplify the term 'dual-path' in arc-agi * Add a claude code skills figure * Migrate images * Update website config * Add automated social media preview * Update social previews logic * update the claude skills figure * Remove 'Google's' from Circle Packing * Clarify unicorn optimization details and model version * Make title as a gradiuent * Fixed the unicorn alignment * Fix side info diagram loading * Update conclusion to talk about many optimization backends. Update Discord+Slack Links * Update the lead in and intro * Apply gradient to optimize_anything * Add * Move figure below. Reorder case studies * Update list order * Make the unicorn demo at the top * Fix the empty line * Talk about Gemini-Flash in ARC-AGI * Update title to A Universal API for Optimizing any Text Parameter * update plot * CHange Why -> How * Add examples from luke except kernelbench * Update the circle packing graphs (white backgrounds) * Revert the Claude Code Skills figure * Update skills blog and webicon * Change charts * Add toc * Add table of content * Make icons right aligned * Refine appendix texts * Add the compute info for arc agi optimization * Add the compute info for arc agi optimization * Update Discord links * Update padding * Add 3d unicorn tutorial * Delete useless files * Remove files * Fix typing issues * Delete useless files * Delete wandb from git * Update docs * Remove the traces * Fix typos * remove useless files * Update README.md --------- Co-authored-by: Lakshya A Agrawal <lakshyaaagrawal@berkeley.edu> Co-authored-by: Donghyun Lee <lukeleeai@gmail.com> Co-authored-by: Shangyint <shangyin@berkeley.edu> Co-authored-by: (Luke) Donghyun Lee <lukedhlee@berkeley.edu> Co-authored-by: Karim Elmaaroufi <elmaaroufi@berkeley.edu> Co-authored-by: Wenjie Ma <windsey@berkeley.edu> Co-authored-by: HackMD <37423+hackmd-hub[bot]@users.noreply.github.com> Co-authored-by: Rohit Sandadi <rohitsandadi@berkeley.edu>")`optimize_anything`[and GEPA for Agent Skills Optimization (](https://github.com/gepa-ai/gepa/commit/5463a1f5a0880a4dd1330f239870bf647122c329 "Launch `optimize_anything` and GEPA for Agent Skills Optimization (#214) * Add blog templates * Add optimize_anything D1 * Update title * Modify Arc-AGI * Update the strip * Revise optimize_anything blog post and update author URL for Luke Correct results statements for circle packing and ARC AGI. Add comments for Wenjie. Simplify the pelican demo code. Change fitness_fn to evaluate. * first ver * Rename the variables for the pelican demo code * Fix * Reduce space between fig and caption * TODO: Lakshya to review this commit * Update title and refine pelican demo description Change title from \"Text Optimization\" to \"Any Text Optimization\". Update pelican demo to clarify that we directly optimize SVG code rather than prompts. Explain that VLM evaluator only sees rendered image, not code, while reflection model optimizes the source. Correct initial seed description to \"Zero-shot attempt from Gemini 3 Pro\". Update ASI reference to use `gepa.image.Image` and specify VLM. Add note about natural language aspect definitions * Improve Appendix handling * Merge with the collapsible appendix * Add auto-deploy for staging * Update blogpost deployment workflow * Add notes to the optuna and circle packing appendices * Add flare to blog button * Update ADRS figures * update the plot layout * Update agent skills * Update ASI diagram * a a * Revert \"a\" This reverts commit a1d51eed2c552dcd82ff70e7f5158f5666f8ce7f. * Update VLM example to Gemini Flash 3 for more dramatic effect. Also include Claude but lower it. Add SVG final code in drop down * Divide the Optuna appendix code section into four components. Add a <section class=scrollable-code markdown> for compactly presenting optimized artifacts. * Divide the Optuna appendix code section into four components. Add a <section class=scrollable-code markdown> for compactly presenting optimized artifacts. * Extract appendix code sections into separate snippet files - Move six appendix examples into individual .snippet files under appendix/ - Replace inline content with MkDocs snippet includes (--8<--) - Move figure captions inline under each image instead of shared caption below - Align side-by-side cloud figures to flex-start instead of center * Update VLM example captions to remove candidate counts and fix grammar * Add more explanation for each appendix section (mathematical, circle packing, kernelbench, aime, arc-agi) * Fix the kernelbench link * Add gitattributes * Update appendix * Update appendix * Add a GPU info to kernel bench * Change evolve to optimize * Update ASI for appendices * Update About page * Refine texts * Refine texts * Refine texts * Refine texts * Simplify the optuna terms (trials -> evaluations. seeds -> independent runs). Clarify that the full optimized artifacts can be found in the appendix along with the codes * Add a footnote function. * Update landing * Update FAQ * Update landing page * Update * Update About page * add more color changes * update skills blog * Address Comment 1: The first paragraph needs to have the main result or takeaway. Otherwise you’ll lose people. Why do we care about this? We need to say that optimize_anything is competitive with the SOTA in each domain and enables new optimization tasks or something * Add declarative aspect * Add kernelbench single vs batch mode analysis in the results section * Update the optimized artifact for the kernel bench * Move optuna below * Refine texts + Simplifed the Optuna terms * Refine texts * Update * Refine texts * Add the optimized ARC-AGI diagram * Refine the kernelbench results section * Address comment: This reads like a research paper intro, not a blog. We don’t need so many super detailed one decimal point numbers on random academic tasks. What’s the high level takeaway, especially for practitioners? As soon as you go into this “paper writing” mode, readers will shift from “this might be some interesting concept” to “this is just grad students trying to hill climb benchmarks”. * Add ARC AGI diagram * Update the ARC AGI diagram * Update VLM * Split ADRS into 2 appendix * U * Split SVG example into 3 sections with explanatory text * Title the code blocks * Edit circle packing code * Edit circle packing code * Refine texts * Edit Luke sections * Address feedback: > From Evolution to Intelligent Design This just comes out of nowhere and you don’t explicitly point out that existing “evolution” systems already do this. Extremely confusing. > optimize_anything API I would put this before the intelligent design thing. At this point in the post it’s been two pages and you STILL haven’t shown people what your thing is and an example of using it. How can it be an amazing simple API if it takes so long to explain? Show first, philosophize later. * Bring SVG earlier * Address: Please show at least one example of USING this API before you get into more philosophy on how it works. Ideally you have one in the first section where you show each API, and you also explain at least one use case for each of the search modes. I’m not saying a whole code example, just say in words what the parameter and objective and side info is, and what kind of performance gain one can get. It can also link to the actual code example later in the post or on GitHub. * rename + add results early for gskill * skills blog changes * Move Evo->ID down below demo. Update diagram * Update the order * Add auto social rendering * Update main.html * Add LLM-based seed candidate generation when seed_candidate=None When seed_candidate is not provided, the reflection LLM generates the initial candidate using the objective, optional background, and up to 3 dataset examples as context. This is a one-time generation step before the optimization loop; the rest of the pipeline stays unchanged. - Make seed_candidate parameter optional (str | Candidate | None) - Add _build_seed_generation_prompt() and _generate_seed_candidate() helpers - Validate that objective and reflection_lm are provided when seed is None - Add 15 tests covering unit, validation, and integration scenarios * Update the evolution -> id section * Make evaluator the first positional arg and seed_candidate optional * Update the blackbox code * staged author css changes * color and snippet * add staging * fix branches names * rename file so mkdocs will compile * Changes * Add ADRS examples * Update ADRS code example * Improve section titles * Merge pareto back into Evolution section * Remove mediocre * Update the print() debugging part * Remove Gemini Pelican * Add unicorn seedless optimization example and tutorial * Add links showing proof points about open/shinka evolve * test-set -> test set * Update the circle packing claim * Improve the objective description * Add examples. Simplify the term 'dual-path' in arc-agi * Add a claude code skills figure * Migrate images * Update website config * Add automated social media preview * Update social previews logic * update the claude skills figure * Remove 'Google's' from Circle Packing * Clarify unicorn optimization details and model version * Make title as a gradiuent * Fixed the unicorn alignment * Fix side info diagram loading * Update conclusion to talk about many optimization backends. Update Discord+Slack Links * Update the lead in and intro * Apply gradient to optimize_anything * Add * Move figure below. Reorder case studies * Update list order * Make the unicorn demo at the top * Fix the empty line * Talk about Gemini-Flash in ARC-AGI * Update title to A Universal API for Optimizing any Text Parameter * update plot * CHange Why -> How * Add examples from luke except kernelbench * Update the circle packing graphs (white backgrounds) * Revert the Claude Code Skills figure * Update skills blog and webicon * Change charts * Add toc * Add table of content * Make icons right aligned * Refine appendix texts * Add the compute info for arc agi optimization * Add the compute info for arc agi optimization * Update Discord links * Update padding * Add 3d unicorn tutorial * Delete useless files * Remove files * Fix typing issues * Delete useless files * Delete wandb from git * Update docs * Remove the traces * Fix typos * remove useless files * Update README.md --------- Co-authored-by: Lakshya A Agrawal <lakshyaaagrawal@berkeley.edu> Co-authored-by: Donghyun Lee <lukeleeai@gmail.com> Co-authored-by: Shangyint <shangyin@berkeley.edu> Co-authored-by: (Luke) Donghyun Lee <lukedhlee@berkeley.edu> Co-authored-by: Karim Elmaaroufi <elmaaroufi@berkeley.edu> Co-authored-by: Wenjie Ma <windsey@berkeley.edu> Co-authored-by: HackMD <37423+hackmd-hub[bot]@users.noreply.github.com> Co-authored-by: Rohit Sandadi <rohitsandadi@berkeley.edu>")[#214](https://github.com/gepa-ai/gepa/pull/214)[)](https://github.com/gepa-ai/gepa/commit/5463a1f5a0880a4dd1330f239870bf647122c329 "Launch `optimize_anything` and GEPA for Agent Skills Optimization (#214) * Add blog templates * Add optimize_anything D1 * Update title * Modify Arc-AGI * Update the strip * Revise optimize_anything blog post and update author URL for Luke Correct results statements for circle packing and ARC AGI. Add comments for Wenjie. Simplify the pelican demo code. Change fitness_fn to evaluate. * first ver * Rename the variables for the pelican demo code * Fix * Reduce space between fig and caption * TODO: Lakshya to review this commit * Update title and refine pelican demo description Change title from \"Text Optimization\" to \"Any Text Optimization\". Update pelican demo to clarify that we directly optimize SVG code rather than prompts. Explain that VLM evaluator only sees rendered image, not code, while reflection model optimizes the source. Correct initial seed description to \"Zero-shot attempt from Gemini 3 Pro\". Update ASI reference to use `gepa.image.Image` and specify VLM. Add note about natural language aspect definitions * Improve Appendix handling * Merge with the collapsible appendix * Add auto-deploy for staging * Update blogpost deployment workflow * Add notes to the optuna and circle packing appendices * Add flare to blog button * Update ADRS figures * update the plot layout * Update agent skills * Update ASI diagram * a a * Revert \"a\" This reverts commit a1d51eed2c552dcd82ff70e7f5158f5666f8ce7f. * Update VLM example to Gemini Flash 3 for more dramatic effect. Also include Claude but lower it. Add SVG final code in drop down * Divide the Optuna appendix code section into four components. Add a <section class=scrollable-code markdown> for compactly presenting optimized artifacts. * Divide the Optuna appendix code section into four components. Add a <section class=scrollable-code markdown> for compactly presenting optimized artifacts. * Extract appendix code sections into separate snippet files - Move six appendix examples into individual .snippet files under appendix/ - Replace inline content with MkDocs snippet includes (--8<--) - Move figure captions inline under each image instead of shared caption below - Align side-by-side cloud figures to flex-start instead of center * Update VLM example captions to remove candidate counts and fix grammar * Add more explanation for each appendix section (mathematical, circle packing, kernelbench, aime, arc-agi) * Fix the kernelbench link * Add gitattributes * Update appendix * Update appendix * Add a GPU info to kernel bench * Change evolve to optimize * Update ASI for appendices * Update About page * Refine texts * Refine texts * Refine texts * Refine texts * Simplify the optuna terms (trials -> evaluations. seeds -> independent runs). Clarify that the full optimized artifacts can be found in the appendix along with the codes * Add a footnote function. * Update landing * Update FAQ * Update landing page * Update * Update About page * add more color changes * update skills blog * Address Comment 1: The first paragraph needs to have the main result or takeaway. Otherwise you’ll lose people. Why do we care about this? We need to say that optimize_anything is competitive with the SOTA in each domain and enables new optimization tasks or something * Add declarative aspect * Add kernelbench single vs batch mode analysis in the results section * Update the optimized artifact for the kernel bench * Move optuna below * Refine texts + Simplifed the Optuna terms * Refine texts * Update * Refine texts * Add the optimized ARC-AGI diagram * Refine the kernelbench results section * Address comment: This reads like a research paper intro, not a blog. We don’t need so many super detailed one decimal point numbers on random academic tasks. What’s the high level takeaway, especially for practitioners? As soon as you go into this “paper writing” mode, readers will shift from “this might be some interesting concept” to “this is just grad students trying to hill climb benchmarks”. * Add ARC AGI diagram * Update the ARC AGI diagram * Update VLM * Split ADRS into 2 appendix * U * Split SVG example into 3 sections with explanatory text * Title the code blocks * Edit circle packing code * Edit circle packing code * Refine texts * Edit Luke sections * Address feedback: > From Evolution to Intelligent Design This just comes out of nowhere and you don’t explicitly point out that existing “evolution” systems already do this. Extremely confusing. > optimize_anything API I would put this before the intelligent design thing. At this point in the post it’s been two pages and you STILL haven’t shown people what your thing is and an example of using it. How can it be an amazing simple API if it takes so long to explain? Show first, philosophize later. * Bring SVG earlier * Address: Please show at least one example of USING this API before you get into more philosophy on how it works. Ideally you have one in the first section where you show each API, and you also explain at least one use case for each of the search modes. I’m not saying a whole code example, just say in words what the parameter and objective and side info is, and what kind of performance gain one can get. It can also link to the actual code example later in the post or on GitHub. * rename + add results early for gskill * skills blog changes * Move Evo->ID down below demo. Update diagram * Update the order * Add auto social rendering * Update main.html * Add LLM-based seed candidate generation when seed_candidate=None When seed_candidate is not provided, the reflection LLM generates the initial candidate using the objective, optional background, and up to 3 dataset examples as context. This is a one-time generation step before the optimization loop; the rest of the pipeline stays unchanged. - Make seed_candidate parameter optional (str | Candidate | None) - Add _build_seed_generation_prompt() and _generate_seed_candidate() helpers - Validate that objective and reflection_lm are provided when seed is None - Add 15 tests covering unit, validation, and integration scenarios * Update the evolution -> id section * Make evaluator the first positional arg and seed_candidate optional * Update the blackbox code * staged author css changes * color and snippet * add staging * fix branches names * rename file so mkdocs will compile * Changes * Add ADRS examples * Update ADRS code example * Improve section titles * Merge pareto back into Evolution section * Remove mediocre * Update the print() debugging part * Remove Gemini Pelican * Add unicorn seedless optimization example and tutorial * Add links showing proof points about open/shinka evolve * test-set -> test set * Update the circle packing claim * Improve the objective description * Add examples. Simplify the term 'dual-path' in arc-agi * Add a claude code skills figure * Migrate images * Update website config * Add automated social media preview * Update social previews logic * update the claude skills figure * Remove 'Google's' from Circle Packing * Clarify unicorn optimization details and model version * Make title as a gradiuent * Fixed the unicorn alignment * Fix side info diagram loading * Update conclusion to talk about many optimization backends. Update Discord+Slack Links * Update the lead in and intro * Apply gradient to optimize_anything * Add * Move figure below. Reorder case studies * Update list order * Make the unicorn demo at the top * Fix the empty line * Talk about Gemini-Flash in ARC-AGI * Update title to A Universal API for Optimizing any Text Parameter * update plot * CHange Why -> How * Add examples from luke except kernelbench * Update the circle packing graphs (white backgrounds) * Revert the Claude Code Skills figure * Update skills blog and webicon * Change charts * Add toc * Add table of content * Make icons right aligned * Refine appendix texts * Add the compute info for arc agi optimization * Add the compute info for arc agi optimization * Update Discord links * Update padding * Add 3d unicorn tutorial * Delete useless files * Remove files * Fix typing issues * Delete useless files * Delete wandb from git * Update docs * Remove the traces * Fix typos * remove useless files * Update README.md --------- Co-authored-by: Lakshya A Agrawal <lakshyaaagrawal@berkeley.edu> Co-authored-by: Donghyun Lee <lukeleeai@gmail.com> Co-authored-by: Shangyint <shangyin@berkeley.edu> Co-authored-by: (Luke) Donghyun Lee <lukedhlee@berkeley.edu> Co-authored-by: Karim Elmaaroufi <elmaaroufi@berkeley.edu> Co-authored-by: Wenjie Ma <windsey@berkeley.edu> Co-authored-by: HackMD <37423+hackmd-hub[bot]@users.noreply.github.com> Co-authored-by: Rohit Sandadi <rohitsandadi@berkeley.edu>") | Feb 19, 2026 |
| [.gitignore](https://github.com/gepa-ai/gepa/blob/main/.gitignore ".gitignore") | [.gitignore](https://github.com/gepa-ai/gepa/blob/main/.gitignore ".gitignore") | [Parallel Proposals (](https://github.com/gepa-ai/gepa/commit/5692976b9c9b6e3c3fec12e962fccf527fdd461a "Parallel Proposals (#314) * feat: add parallel proposal execution to reflective mutation Split ReflectiveMutationProposer.propose() into three phases: - prepare_proposal() (sequential): candidate selection, minibatch sampling - execute_proposal() (thread-safe): evaluate-reflect-propose-evaluate pipeline - apply_proposal_output() (sequential): deferred state updates Add num_parallel_proposals to GEPAEngine and EngineConfig. When > 1, multiple proposals are sampled and executed concurrently via ThreadPoolExecutor, then acceptances are processed sequentially. * fix: make mlflow logging thread-safe for parallel proposals mlflow.active_run() is thread-local, so parallel proposal threads were auto-creating new mlflow runs when calling log_metrics(). Fix: capture run_id at start_run() time and use MlflowClient with explicit run_id for all logging operations (metrics, params, artifacts). Also fix ruff lint issues from conflict resolution. * chore: add outputs/ to gitignore * fix: resolve pyright type errors in engine and experiment_tracker * fix: test failures from parallel proposal merge - Add num_metric_calls field to EvaluationBatch and set it in adapter - Fix mlflow logging to fall back to fluent API when MlflowClient not available (preserves backward compat for tests that don't call start_run) - Restore is_active() to check mlflow.active_run() for correct end_run semantics * revert: remove num_metric_calls — not on main, not needed * fix: use MlflowClient.log_metric (singular) instead of nonexistent log_metrics * fix: remove double-counting of evals in proposer (conflict resolution artifact) * fix: pass tracking_uri to MlflowClient to avoid default sqlite registry error * fix: gracefully handle MlflowClient creation failure in test environments * feat: add \"auto\" mode for num_parallel_proposals When set to \"auto\", computes num_parallel_proposals as max(1, max_workers // (2 * minibatch_size)) to fill the worker pool without oversubscribing. Each proposal does ~2 eval batches, so this balances parallelism with budget. Default remains 1 (sequential) for backward compatibility. * fix: auto parallel proposals should be max_workers // minibatch_size (no /2) * fix: remove None fallbacks from parallel proposals resolver — values are always resolved * fix: narrow int|None to int at call site for pyright")[#314](https://github.com/gepa-ai/gepa/pull/314)[)](https://github.com/gepa-ai/gepa/commit/5692976b9c9b6e3c3fec12e962fccf527fdd461a "Parallel Proposals (#314) * feat: add parallel proposal execution to reflective mutation Split ReflectiveMutationProposer.propose() into three phases: - prepare_proposal() (sequential): candidate selection, minibatch sampling - execute_proposal() (thread-safe): evaluate-reflect-propose-evaluate pipeline - apply_proposal_output() (sequential): deferred state updates Add num_parallel_proposals to GEPAEngine and EngineConfig. When > 1, multiple proposals are sampled and executed concurrently via ThreadPoolExecutor, then acceptances are processed sequentially. * fix: make mlflow logging thread-safe for parallel proposals mlflow.active_run() is thread-local, so parallel proposal threads were auto-creating new mlflow runs when calling log_metrics(). Fix: capture run_id at start_run() time and use MlflowClient with explicit run_id for all logging operations (metrics, params, artifacts). Also fix ruff lint issues from conflict resolution. * chore: add outputs/ to gitignore * fix: resolve pyright type errors in engine and experiment_tracker * fix: test failures from parallel proposal merge - Add num_metric_calls field to EvaluationBatch and set it in adapter - Fix mlflow logging to fall back to fluent API when MlflowClient not available (preserves backward compat for tests that don't call start_run) - Restore is_active() to check mlflow.active_run() for correct end_run semantics * revert: remove num_metric_calls — not on main, not needed * fix: use MlflowClient.log_metric (singular) instead of nonexistent log_metrics * fix: remove double-counting of evals in proposer (conflict resolution artifact) * fix: pass tracking_uri to MlflowClient to avoid default sqlite registry error * fix: gracefully handle MlflowClient creation failure in test environments * feat: add \"auto\" mode for num_parallel_proposals When set to \"auto\", computes num_parallel_proposals as max(1, max_workers // (2 * minibatch_size)) to fill the worker pool without oversubscribing. Each proposal does ~2 eval batches, so this balances parallelism with budget. Default remains 1 (sequential) for backward compatibility. * fix: auto parallel proposals should be max_workers // minibatch_size (no /2) * fix: remove None fallbacks from parallel proposals resolver — values are always resolved * fix: narrow int|None to int at call site for pyright") | Apr 8, 2026 |
| [.pre-commit-config.yaml](https://github.com/gepa-ai/gepa/blob/main/.pre-commit-config.yaml ".pre-commit-config.yaml") | [.pre-commit-config.yaml](https://github.com/gepa-ai/gepa/blob/main/.pre-commit-config.yaml ".pre-commit-config.yaml") | [ARC-AGI](https://github.com/gepa-ai/gepa/commit/575ce3379bffdedc16bd6316b990a459a3576b44 "ARC-AGI") | Sep 1, 2025 |
| [AGENTS.md](https://github.com/gepa-ai/gepa/blob/main/AGENTS.md "AGENTS.md") | [AGENTS.md](https://github.com/gepa-ai/gepa/blob/main/AGENTS.md "AGENTS.md") | [Update frontpage](https://github.com/gepa-ai/gepa/commit/1f24f46ce70e5d0da37799709a973e9e70d87246 "Update frontpage") | Feb 6, 2026 |
| [CITATION.cff](https://github.com/gepa-ai/gepa/blob/main/CITATION.cff "CITATION.cff") | [CITATION.cff](https://github.com/gepa-ai/gepa/blob/main/CITATION.cff "CITATION.cff") | [Initial commit](https://github.com/gepa-ai/gepa/commit/89fad86bf3a2467b99c066b35f517d5f7f4aa78d "Initial commit") | Aug 5, 2025 |
| [CLAUDE.md](https://github.com/gepa-ai/gepa/blob/main/CLAUDE.md "CLAUDE.md") | [CLAUDE.md](https://github.com/gepa-ai/gepa/blob/main/CLAUDE.md "CLAUDE.md") | [Add agents.md and claude.md](https://github.com/gepa-ai/gepa/commit/35e53f9814aa1ec9d754676244fc067fbc663877 "Add agents.md and claude.md") | Feb 6, 2026 |
| [CONTRIBUTING.md](https://github.com/gepa-ai/gepa/blob/main/CONTRIBUTING.md "CONTRIBUTING.md") | [CONTRIBUTING.md](https://github.com/gepa-ai/gepa/blob/main/CONTRIBUTING.md "CONTRIBUTING.md") | [Add py.typed](https://github.com/gepa-ai/gepa/commit/554bf0078c5e78185ebec4b759784fb05cb62040 "Add py.typed") | Nov 6, 2025 |
| [LICENSE](https://github.com/gepa-ai/gepa/blob/main/LICENSE "LICENSE") | [LICENSE](https://github.com/gepa-ai/gepa/blob/main/LICENSE "LICENSE") | [Initial commit](https://github.com/gepa-ai/gepa/commit/89fad86bf3a2467b99c066b35f517d5f7f4aa78d "Initial commit") | Aug 5, 2025 |
| [README.md](https://github.com/gepa-ai/gepa/blob/main/README.md "README.md") | [README.md](https://github.com/gepa-ai/gepa/blob/main/README.md "README.md") | [fix: update README logo to new design (with text) (](https://github.com/gepa-ai/gepa/commit/1553fcfb69342f1d492f3830b5e961b49c99ac4e "fix: update README logo to new design (with text) (#342) Point to docs/docs/assets/gepa_logo_with_text.svg which matches the docs website landing page. Co-authored-by: Lakshya A Agrawal <lakshyaaagrawal+gepabot@berkeley.edu> Co-authored-by: Claude Opus 4.6 (1M context) <noreply@anthropic.com>")[#342](https://github.com/gepa-ai/gepa/pull/342)[)](https://github.com/gepa-ai/gepa/commit/1553fcfb69342f1d492f3830b5e961b49c99ac4e "fix: update README logo to new design (with text) (#342) Point to docs/docs/assets/gepa_logo_with_text.svg which matches the docs website landing page. Co-authored-by: Lakshya A Agrawal <lakshyaaagrawal+gepabot@berkeley.edu> Co-authored-by: Claude Opus 4.6 (1M context) <noreply@anthropic.com>") | Apr 21, 2026 |
| [pyproject.toml](https://github.com/gepa-ai/gepa/blob/main/pyproject.toml "pyproject.toml") | [pyproject.toml](https://github.com/gepa-ai/gepa/blob/main/pyproject.toml "pyproject.toml") | [docs: add Decagon production blog (](https://github.com/gepa-ai/gepa/commit/bf1a159acea6b185fd713452c09b0cc59e06e317 "docs: add Decagon production blog (#334) * docs: add Decagon production blog to use cases and landing page Add Decagon's \"Optimizing GEPA for Production\" blog post to the community tutorials section and company carousel. Co-Authored-By: Claude Opus 4.6 (1M context) <noreply@anthropic.com> * fix: pin pandas>=3.0.0 for Python 3.14+ to fix CI build failure pandas 2.3.2 (pulled by datasets) fails to build from source on Python 3.14 with newer meson versions on GitHub runners. pandas 3.0.2 has native 3.14 support with pre-built wheels. Co-Authored-By: Claude Opus 4.6 (1M context) <noreply@anthropic.com> * fix: relax pandas pin to >=2.3.3 for Python 3.14+ pandas 2.3.3 is the first version with pre-built cp314 wheels. 2.3.2 fails to build from source due to a meson incompatibility. No need to jump to 3.0.0. Co-Authored-By: Claude Opus 4.6 (1M context) <noreply@anthropic.com> --------- Co-authored-by: Lakshya A Agrawal <lakshyaaagrawal+gepabot@berkeley.edu> Co-authored-by: Claude Opus 4.6 (1M context) <noreply@anthropic.com>")[#334](https://github.com/gepa-ai/gepa/pull/334)[)](https://github.com/gepa-ai/gepa/commit/bf1a159acea6b185fd713452c09b0cc59e06e317 "docs: add Decagon production blog (#334) * docs: add Decagon production blog to use cases and landing page Add Decagon's \"Optimizing GEPA for Production\" blog post to the community tutorials section and company carousel. Co-Authored-By: Claude Opus 4.6 (1M context) <noreply@anthropic.com> * fix: pin pandas>=3.0.0 for Python 3.14+ to fix CI build failure pandas 2.3.2 (pulled by datasets) fails to build from source on Python 3.14 with newer meson versions on GitHub runners. pandas 3.0.2 has native 3.14 support with pre-built wheels. Co-Authored-By: Claude Opus 4.6 (1M context) <noreply@anthropic.com> * fix: relax pandas pin to >=2.3.3 for Python 3.14+ pandas 2.3.3 is the first version with pre-built cp314 wheels. 2.3.2 fails to build from source due to a meson incompatibility. No need to jump to 3.0.0. Co-Authored-By: Claude Opus 4.6 (1M context) <noreply@anthropic.com> --------- Co-authored-by: Lakshya A Agrawal <lakshyaaagrawal+gepabot@berkeley.edu> Co-authored-by: Claude Opus 4.6 (1M context) <noreply@anthropic.com>") | Apr 15, 2026 |
| [pyrightconfig.json](https://github.com/gepa-ai/gepa/blob/main/pyrightconfig.json "pyrightconfig.json") | [pyrightconfig.json](https://github.com/gepa-ai/gepa/blob/main/pyrightconfig.json "pyrightconfig.json") | [feat: ConfidenceAdapter — logprob-aware scoring and reflection for cl…](https://github.com/gepa-ai/gepa/commit/65df4325e3fb4781cf2ab17dd144d6ce2f7b98fe "feat: ConfidenceAdapter — logprob-aware scoring and reflection for classification tasks (#258) * feat: add ConfidenceAdapter for logprob-aware classification optimization Add a new adapter that uses token-level log-probabilities from structured JSON outputs to detect and penalize \"lucky guesses\" in classification tasks. When an LLM answers correctly but with low confidence, the adapter lowers the score so GEPA evolves prompts that produce genuinely reliable classifications, not just ones that happen to be right. Key components: - ConfidenceAdapter: extracts joint_logprob via llm-structured-confidence, blends correctness with confidence, and feeds rich diagnostic feedback (logprob, probability, top alternatives) into the reflection LLM - ScoringStrategy protocol with three built-in implementations: LinearBlendScoring, ThresholdScoring, SigmoidScoring - Multi-objective support: exposes accuracy, logprob, and probability for Pareto-efficient selection - Optional dependency extra: pip install \"gepa[confidence]\" - Full test suite and comprehensive documentation (API reference + guide) Made-with: Cursor * docs: clarify scoring pipeline and add formulas/tables for all strategies Add a \"From Logprob to Score\" section that explains the three-step pipeline (joint_logprob → probability → score) with an ASCII diagram. Expand each scoring strategy with its exact formula, a table showing joint logprob → probability → score for concrete examples, and a \"Why\" column explaining the reasoning. This ensures users never need to read the source code to understand how scoring works. Made-with: Cursor * docs: add ConfidenceAdapter to README adapter tables Add the new adapter to both the \"Built-in adapters\" summary table and the \"Contributed Adapters\" detailed list, with links to the source code, the llm-structured-confidence library, and the documentation guide. Made-with: Cursor * docs: clarify that logprobs are confidence scores, not calibrated probabilities Add a warning admonition explaining that exp(joint_logprob) should be treated as a confidence score (useful for ranking) rather than a calibrated probability, and point users to Platt scaling, isotonic regression, and temperature scaling for true probability estimates. Made-with: Cursor * fix: skip confidence tests and type-check when extra not installed The CI installs only `--extra dev`, not `--extra confidence`, so: - Add `confidence_adapter` to pyrightconfig.json exclude list (same pattern as dspy, rag, anymaths, terminal_bench adapters) - Add `pytest.importorskip(\"llm_structured_confidence\")` to the adapter test module so tests are skipped instead of failing when the optional dependency is not present Made-with: Cursor * refactor: align ConfidenceAdapter conventions with DefaultAdapter - Inherit from GEPAAdapter[...] explicitly (all other adapters do) - Type-annotate propose_new_texts: ProposalFn | None - Rename response_text → full_assistant_response (match DefaultAdapter) - Rename litellm_completion_kwargs → litellm_batch_completion_kwargs - Reorder ConfidenceDataInst fields to match DefaultDataInst - Remove dead _call_llm method (evaluate uses batch_completion) - Add try/except for callable model errors in evaluate() - Handle Exception objects from batch_completion in DefaultAdapter - Rewrite tests: callable models instead of _call_llm mocks, updated assertions for new feedback format and objective_scores - Apply ruff formatting, pass pyright with 0 errors All 445 tests pass. Made-with: Cursor * docs: add ConfidenceAdapter benchmark example with results Add reproducible comparison of ConfidenceAdapter vs DefaultAdapter across AG News (4-class), Emotion (6-class), and Rotten Tomatoes (binary). Includes pre-computed results: evaluation CSVs, optimization JSONs, charts, and a detailed README addressing the PR review request. ConfidenceAdapter shows +2.10pp accuracy on AG News and +1.80pp on Emotion, with tied performance on Rotten Tomatoes. Made-with: Cursor * docs: expand README with full analysis, charts, and per-class results Embed all charts inline so the study renders directly on GitHub. Include per-class tables for all three datasets, threshold calibration explanation, feedback design, and generalization tradeoff analysis. Made-with: Cursor * revert: restore default_adapter.py to upstream version Remove the litellm.batch_completion changes from DefaultAdapter. These changes (direct litellm usage + exception handling) will go in a separate branch to avoid conflicts with upstream main. Made-with: Cursor * docs: add DefaultAdapter to confidence distribution chart Show both adapters side-by-side (2x3 grid) so readers can compare how the optimized prompts affect the confidence distribution of correct vs incorrect predictions. Made-with: Cursor * docs: add confidence distribution analysis with numerical breakdown Explain that the two adapters produce nearly identical confidence distributions — the advantage comes from which examples the prompt gets right, not from overall confidence calibration. Made-with: Cursor * docs: explain how to interpret confidence distribution gap Clarify that a large gap means good calibration (model knows when it's wrong) and that the small gap observed indicates poor calibration, justifying the high 0.99 threshold. Made-with: Cursor * docs: add benchmark blog post, update guide and examples - Add blog post comparing ConfidenceAdapter vs DefaultAdapter across AG News, Emotion, and Rotten Tomatoes with detailed analysis, charts, and logprobs explanation - Update confidence-adapter guide: fix feedback examples to match code, add threshold calibration section, document all adapter parameters, fix Quick Start defaults - Add per-class precision charts for consistency with recall and F1 - Fix convergence chart layout (x-axis label was cut off) - Regenerate metrics comparison chart with vertical layout - Simplify examples README, remove duplicated charts from outputs - Add author entry to .authors.yml Made-with: Cursor * docs: add ConfidenceAdapter tutorial notebook with failfast and proxy config - New Jupyter notebook tutorial (AG News only) comparing DefaultAdapter vs ConfidenceAdapter end-to-end with confidence plots and per-class metrics - Centralized USE_LITELLM_PROXY flag and PROVIDER_KWARGS in both the notebook and examples/confidence_adapter/main.py — replaces scattered PROXY comments - Failfast checks for task and reflection models before spending optimization budget, with automatic thinking-payload discovery for the reflection LM - Add MAX_ITERATIONS config for easy iteration count control - Link tutorial from blog post and tutorials index; add to mkdocs nav - Copy upstream gepa.lm module needed by DefaultAdapter Made-with: Cursor * fix: address review feedback on ConfidenceAdapter 1. Fix guide: claimed 3 objectives but code exposes 2 (accuracy, probability) — removed incorrect `logprob` from docs 2. Validate response_format is provided when model is a string — raises ValueError instead of silent failures 3. Add note that describe() on ScoringStrategy is not currently called by the adapter (kept for user diagnostics) 4. Fix blog post: extract_confidence → extract_logprobs to match actual adapter usage 5. Trim 100-line module docstring to a brief summary linking to the full guide Co-Authored-By: Claude Opus 4.6 (1M context) <noreply@anthropic.com> --------- Co-authored-by: Lakshya A Agrawal <lakshyaaagrawal@berkeley.edu> Co-authored-by: Lakshya A Agrawal <lakshyaaagrawal+gepabot@berkeley.edu> Co-authored-by: Claude Opus 4.6 (1M context) <noreply@anthropic.com>") | Apr 14, 2026 |
| [uv.lock](https://github.com/gepa-ai/gepa/blob/main/uv.lock "uv.lock") | [uv.lock](https://github.com/gepa-ai/gepa/blob/main/uv.lock "uv.lock") | [Add](https://github.com/gepa-ai/gepa/commit/b2b613ea189e72867d085b93614b3e626e4ccd8b "Add `optimize_anything`: unified high-level API for GEPA (#204) * v0 * Add working optimize_anything api * Fix type errors * Update uv.lock * ruff fix * Fix tests * Fix typo * Add custom instruction proposer * Add custom instruction proposer * Move towards custom instruction proposers * Fix test * Fix typing * Implement multi-objective scores * Improve template * Adding a polynomial minimization example * Adding a polynomial minimization example * Add a simple readme for the polynomial example * Add details on the polynomial example readme * Add logic for counting the number of evaluation calls * Add arc-agi and circle packing into examples * Add math prompt optimization example * Add optimize anything blogpost notebook * Refactored the math prompt optimization example * refactor arc_agi example * Refactored ARC-AGI example * Add minimal notebook blogs (WIP) * Incorporated minimal code examples (prompt + agent) into the main blog notebook * Incorporated minimal code examples (prompt + agent) into the main blog notebook * Add figures for blog * fitness_fn is now scalar * Update the arc agi prompt to be compatible with optimize_anything api * Add aime + arc agi plots for blog * Add aime + arc agi plots for blog * Minor change in notebook * Add polynomial grah * Minor * Add new blog figures (aime, arc agi, polynomial, and circle packing (26)) * Add new blog figures (aime, arc agi, polynomial, and circle packing (26)) * Add the best program example to the blog * Update the intro of the blog by adding a brief problem desc and restructuring the abstract * Update the blog: simplyfing the demo code * Update blog * Update the circle packing example code to use a refiner prompt evolution * Add objective and background * Add cant_be_late for ADRS example * Make dataset optional * Add common code execution utils * Update the blog * Add evaluation_cache to optimize_anything.py * Pass example as kwarg to support dataset=None mode; Handle EOFError when subprocess crashes before writing results for code_execution.py * Fix subprocess pickle errors: filter non-picklable objects, handle empty results * Add README for ADRS example * Remove old wandb * Add requirements for simulators * Ruff * Add all the latest examples codes into the blog notebook * Add the latest experiments results (aime, circle packing 26, and polynomial) into the blog folder * Add latest blog experiment results * Add kernelbench and the latest codes for the blog * Add blog experimnets outputs inside examples * Add cloudcast example * Add ADRS examples and blogpost * Update can't be late plots * Update noteboook * Delete print statement in these examples * Update cloudcast results * Add refiner * Add latest plots from kernel bench and arc agi * git commit -m \"Add RefinerConfig enhancements and example_best_evals warm-start system RefinerConfig improvements: - Add min_refinements to guarantee minimum refinement iterations - Add stop_when for conditional early stopping based on side_info keys - Pass full attempt history to refiner LLM for context - Add DEFAULT_REFINER_PROMPT with {objective}/{background} placeholders - Remove \"stop on no improvement\" default (now runs max_refinements) Warm-start support: - Add example_best_evals_k to EngineConfig (default 10) - Track top-K evaluations per example with thread-safe access - Pass example_best_evals to fitness_fn for warm-start optimization New example: - Add circle_packing_refiner using simplified RefinerConfig API\" error: pathspec 'on' did not match any file(s) known to git error: pathspec 'no' did not match any file(s) known to git error: pathspec 'improvement default (now runs max_refinements) Warm-start support: - Add example_best_evals_k to EngineConfig (default 10) - Track top-K evaluations per example with thread-safe access - Pass example_best_evals to fitness_fn for warm-start optimization New example: - Add circle_packing_refiner using simplified RefinerConfig API' did not match any file(s) known to git * Rename example_best_evals to best_example_evals and add cache_evaluation_storage Parameter renaming for clarity: - example_best_evals_k → best_example_evals_k (in EngineConfig) - example_best_evals → best_example_evals (passed to fitness_fn) Add adapter-level fitness function caching (cache_evaluation_storage): - \"memory\": in-memory dict, lost on restart - \"disk\": pickle files in {run_dir}/fitness_cache/, persists across runs - \"auto\": uses disk if run_dir provided, else memory Files changed: - src/gepa/optimize_anything.py: add CacheEvaluationStorage type, resolve cache mode - optimize_anything_adapter.py: implement caching with thread-safe storage - examples/circle_packing_refiner/: update to use new parameter names - tests/: add test_best_example_evals.py and test_cache_evaluation_storage.py * Simplify RefinerConfig API and improve defaults RefinerConfig: - Remove refiner_prompt (use DEFAULT_REFINER_PROMPT or candidate's prompt) - Remove min_refinements and stop_when - Refinement now runs at least once, stops when no improvement - Default max_refinements = 2 ReflectionConfig: - reflection_minibatch_size defaults to 1 for single-instance mode (dataset=None), 3 otherwise EngineConfig: - best_example_evals_k default = 30 Also surface refiner's multiple metrics (max_score, mean_score, ema_score_fixed, ema_score_adaptive) to objective scores output. * Simplify kernelbench example to use RefinerConfig - Replace manual PromptCache and StateTracker with adapter-based caching - Replace manual refinement loop with RefinerConfig (adapter handles it) - Reduce main.py from 636 to 236 lines (~63% reduction) - Remove RefinerSig from prompts.py (adapter uses DEFAULT_REFINER_PROMPT) - Add run_with_GPUs.py locally instead of importing from parent - Remove docs/ and tests/ directories (outdated after refactor) The simplified version uses: - cache_evaluation=True in EngineConfig for automatic caching - RefinerConfig with max_refinements for automatic refinement - Single-component seed (kernel_gen_prompt only) * Remove old arc_agi and circle_packing examples These are replaced by circle_packing_refiner which uses RefinerConfig. * Update circle_packing_refiner example - Use lowercase \"scores\" key for multi-objective support - Add log directory cleanup on startup - Remove max_refinements override (use default) - Add timeout constraint to BACKGROUND prompt - Comment out debug prints * Refactor adapter and add max_candidate_proposals stopper optimize_anything_adapter.py: - Extract _get_target_param() to avoid code duplication - Consolidate parallel evaluation into _run_parallel() helper - Remove unused _format_evaluation_feedback() method optimize_anything.py: - Add max_candidate_proposals to EngineConfig as stopping condition * Add RefinerConfig tests and ignore outputs/ tests/test_refiner.py: Test suite for RefinerConfig using number guessing scenario - validates caching (memory/disk) and refinement functionality. * Rename arc_agi_poetiq to arc_agi and circle_packing_refiner to circle_packing * Fix arc_agi imports and output paths after rename * Simplify arc_agi and kernelbench examples arc_agi: - Consolidate prompts, dataset loading, TrackedLLM into utils.py - Remove unused __init__.py, cache.py, tracked_llm.py - Remove test files (tests/) kernelbench: - Inline fitness_fn in main.py with run_kernel() and build_side_info() helpers - Remove GPU locking infrastructure (run_with_GPUs.py, GPUManager) - Use simple nvidia-smi polling for sequential execution - Move constants (LLM, TIMEOUT) to prompts.py - Remove argparse, use constants for config * Simplify polynomial example - Consolidate config.py, evaluator.py, prompt.py into main.py - Use constants instead of argparse - Use best_example_evals for warm-start trajectory - Return all_attempts list for trajectory tracking - Clean helpers: execute_code, extract_best_xs, build_side_info * Simplify adrs fitness_fn to return (score, side_info) Remove output from return tuple to match optimize_anything API. Output code is commented out rather than deleted. * Simplify aime_math and circle_packing fitness_fn - aime_math: return (score, side_info) and clean up config defaults - circle_packing: remove debug comments * Fix track_best_outputs by using side_infos instead of None outputs The fitness_fn wrapper normalizes returns to (score, None, side_info), so extracting the middle element always yielded None, which was filtered out by the `output is not None` guard in _update_pareto_front_for_val_id. Use the already-computed side_infos list instead. * Enable refiner by default and refine all params as JSON dict - RefinerConfig enabled by default (set refiner=None to disable) - refiner_lm defaults to reflection_lm when not specified - Auto-inject refiner_prompt into seed candidates - Refiner now refines all non-refiner params together as a JSON dict instead of a single target param - Side info uses best attempt's structure with refiner_prompt_specific_info containing refinement_rate scores - Default reflection_lm to openai/gpt-5.1, use_cloudpickle to True - Add refiner=None to existing tests that don't test refiner - Add new tests: multi-param, dataset mode, frontier types, side_info structure * Update examples to match latest API and remove redundant configs - optimize_linear_function_params: rewrite from old batch API to single-example 2-tuple signature (example, **kwargs) -> (score, side_info) - circle_packing, kernelbench: remove redundant refiner_lm (defaults to reflection_lm now) - adrs/can_be_late, adrs/cloudcast: remove redundant seed=0 and skip_perfect_score=False (already the defaults) - polynomial: add max_candidate_proposals=20 to fix missing stopping condition that would raise ValueError at runtime * Add polynomial utils and update blogpost notebook - Extract polynomial helpers into examples/polynomial/utils.py - Update optimize_anything_blogpost notebook * Fix refiner side_info to show original evaluation for reflection Use original (unrefined) side_info as base so reflection LLM sees raw candidate quality. Replace refinement_rate metrics with actual best scores from refinement attempts. Add full attempt history for refiner_prompt reflection. * Remove verbose refiner print from optimize_anything_adapter * Remove redirect_stdout from fitness_fn wrapper to fix swallowed prints redirect_stdout is not thread-safe and was silently capturing all print output from fitness functions when running with parallel=True, causing logs to be lost. * Add kwargs filtering to fitness_fn wrapper and smoke test script Inspect fitness_fn signature at wrap time to only forward kwargs it accepts (e.g. best_example_evals). Pass example as keyword arg instead of positional to support both `def fn(candidate, example)` and `def fn(candidate, **kwargs)` patterns. Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com> * Disable refiner by default for examples that don't use it Set refiner=None in arc_agi, aime_math, cloudcast, can_be_late, and linear examples since RefinerConfig is now enabled by default. Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com> * Fix refiner LM to use dspy.LM instead of litellm wrapper The refiner requires a dspy.BaseLM instance (used via dspy.context(lm=...)), not a plain callable. Also fix ordering so refiner_lm defaults to reflection_lm string before reflection_lm is converted to a callable. Failed refiner attempts now correctly score 0.0 instead of original_score. Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com> * Add more info to cloudcast * Change cloudcast * Correct notebook * Correct cloudcast * Create diagram * Update to fix CI * Change output format to (score, best_candidate, side_info) tuple - evaluate() now returns outputs as list of (score, best_candidate, side_info) tuples - Without refiner: best_candidate = original candidate - With refiner: best_candidate = winning candidate (original or refined) - _refine_and_evaluate tracks best_candidate dict instead of best_output - trajectories unchanged (still contains side_info for reflection) * Make refiner disabled by default, explicitly enable in examples - Change GEPAConfig.refiner default from RefinerConfig() to None - Change RefinerConfig.max_refinements default from 2 to 1 - Update circle_packing and kernelbench examples to explicitly enable refiner * Migrate refiner from DSPy to LiteLLM for consistency with reflection Remove DSPy dependency for refiner - now uses litellm.completion() directly like reflection_lm. Add REFINER_PROMPT_TEMPLATE constant to format prompts. * Make cloudpickle usage configurable via EngineConfig.use_cloudpickle Add set_use_cloudpickle() to code_execution.py and call it from optimize_anything.py based on config. Allows fallback to standard pickle when cloudpickle isn't needed or causes issues. * Remove verbose print statements from refiner logic Refiner now runs silently without printing iteration details, JSON proposals, or score comparisons to stdout. * Make API Changes * Remove merge * Extract stdio * Migrate cache config * Add tests * Wrapper context manager * Add fixes * Fixes * Fix * Fixes * Typing * iUpdate cloudcast image * Fixes * Fix refiner: remove dead DSPy references, fix scoring for failed attempts - Remove _initialize_refiner() and refiner_predictor (migrated to LiteLLM) - Remove dead `import dspy` that would fail in CI - Filter out failed attempts (no side_info) when picking best refined score - Fix Ruff: import ordering, unused `import sys`, missing strict=False - Use FitnessFn type alias instead of raw Callable * Only include refiner scores when user's side_info has scores Avoids injecting empty \"scores\" into refiner_prompt_specific_info when the user isn't using objective frontier. * Fix evaluator diagnostics on exception and conditional refiner scores Preserve oa.log()/stdout/stderr when evaluator raises instead of discarding them. Only inject \"scores\" in refiner side_info when user's side_info uses objective frontier. * Revert \"Only include refiner scores when user's side_info has scores\" This reverts commit b8b019e884597646ac7459d86270d2fd3f80e8c9. * Revert \"Fix refiner: remove dead DSPy references, fix scoring for failed attempts\" This reverts commit dda7d792b977da5c2874685f3d3c59bbad5d838f. * Trigger CI * Initialize result before try to satisfy Pyright * Fix Pyright return type inference for failure path * Use 0.0 for failure score to match codebase convention * Use isinstance check instead of separate exc variable for Pyright * Update the examples to the latest codes * Respect raise_on_exception in EvaluatorWrapper, update examples to use OptimizationState - Thread raise_on_exception from EngineConfig into EvaluatorWrapper so exceptions propagate when configured instead of being silently absorbed - Move assert callable(refiner_lm) before refinement loop to fail fast - Update circle_packing and polynomial examples to use opt_state parameter - Move extract helpers into respective utils modules * Address luke feedback * Add Image Side info * Add pelican example * Fixes * Add docs * Remove files excluded from PR: examples/, assets/blog/, blogpost, diagram, test script, gitmodules Excluded from optimize_anything_pr branch: - examples/* (all example code and data) - assets/blog/* (blog-related images) - optimize_anything_blogpost.ipynb - optimize_anything_diagram_v2.html - scripts/test_all_examples.py - .gitmodules - .gitignore (restored to main version) Co-authored-by: Cursor <cursoragent@cursor.com> * Add optimize_anything to public API * Change 0 to -1e9 * Fix * Ruff * Add optimize_anything to public API * Fix * Ruff * Ad ddocs * Revert multi seed --------- Co-authored-by: Lakshya A Agrawal <lakshyaaagrawal@berkeley.edu> Co-authored-by: Donghyun Lee <lukeleeai@gmail.com> Co-authored-by: Shangyin Tan <shangyin@berkeley.edu> Co-authored-by: Wenjie Ma <windsey@berkeley.edu> Co-authored-by: Karim Elmaaroufi <k.e@berkeley.edu> Co-authored-by: Wenjie Ma <windsey@berkeley.edu> Co-authored-by: Claude Opus 4.6 <noreply@anthropic.com> Co-authored-by: Cursor <cursoragent@cursor.com>")`optimize_anything`[: unified high-level API for GEPA (](https://github.com/gepa-ai/gepa/commit/b2b613ea189e72867d085b93614b3e626e4ccd8b "Add `optimize_anything`: unified high-level API for GEPA (#204) * v0 * Add working optimize_anything api * Fix type errors * Update uv.lock * ruff fix * Fix tests * Fix typo * Add custom instruction proposer * Add custom instruction proposer * Move towards custom instruction proposers * Fix test * Fix typing * Implement multi-objective scores * Improve template * Adding a polynomial minimization example * Adding a polynomial minimization example * Add a simple readme for the polynomial example * Add details on the polynomial example readme * Add logic for counting the number of evaluation calls * Add arc-agi and circle packing into examples * Add math prompt optimization example * Add optimize anything blogpost notebook * Refactored the math prompt optimization example * refactor arc_agi example * Refactored ARC-AGI example * Add minimal notebook blogs (WIP) * Incorporated minimal code examples (prompt + agent) into the main blog notebook * Incorporated minimal code examples (prompt + agent) into the main blog notebook * Add figures for blog * fitness_fn is now scalar * Update the arc agi prompt to be compatible with optimize_anything api * Add aime + arc agi plots for blog * Add aime + arc agi plots for blog * Minor change in notebook * Add polynomial grah * Minor * Add new blog figures (aime, arc agi, polynomial, and circle packing (26)) * Add new blog figures (aime, arc agi, polynomial, and circle packing (26)) * Add the best program example to the blog * Update the intro of the blog by adding a brief problem desc and restructuring the abstract * Update the blog: simplyfing the demo code * Update blog * Update the circle packing example code to use a refiner prompt evolution * Add objective and background * Add cant_be_late for ADRS example * Make dataset optional * Add common code execution utils * Update the blog * Add evaluation_cache to optimize_anything.py * Pass example as kwarg to support dataset=None mode; Handle EOFError when subprocess crashes before writing results for code_execution.py * Fix subprocess pickle errors: filter non-picklable objects, handle empty results * Add README for ADRS example * Remove old wandb * Add requirements for simulators * Ruff * Add all the latest examples codes into the blog notebook * Add the latest experiments results (aime, circle packing 26, and polynomial) into the blog folder * Add latest blog experiment results * Add kernelbench and the latest codes for the blog * Add blog experimnets outputs inside examples * Add cloudcast example * Add ADRS examples and blogpost * Update can't be late plots * Update noteboook * Delete print statement in these examples * Update cloudcast results * Add refiner * Add latest plots from kernel bench and arc agi * git commit -m \"Add RefinerConfig enhancements and example_best_evals warm-start system RefinerConfig improvements: - Add min_refinements to guarantee minimum refinement iterations - Add stop_when for conditional early stopping based on side_info keys - Pass full attempt history to refiner LLM for context - Add DEFAULT_REFINER_PROMPT with {objective}/{background} placeholders - Remove \"stop on no improvement\" default (now runs max_refinements) Warm-start support: - Add example_best_evals_k to EngineConfig (default 10) - Track top-K evaluations per example with thread-safe access - Pass example_best_evals to fitness_fn for warm-start optimization New example: - Add circle_packing_refiner using simplified RefinerConfig API\" error: pathspec 'on' did not match any file(s) known to git error: pathspec 'no' did not match any file(s) known to git error: pathspec 'improvement default (now runs max_refinements) Warm-start support: - Add example_best_evals_k to EngineConfig (default 10) - Track top-K evaluations per example with thread-safe access - Pass example_best_evals to fitness_fn for warm-start optimization New example: - Add circle_packing_refiner using simplified RefinerConfig API' did not match any file(s) known to git * Rename example_best_evals to best_example_evals and add cache_evaluation_storage Parameter renaming for clarity: - example_best_evals_k → best_example_evals_k (in EngineConfig) - example_best_evals → best_example_evals (passed to fitness_fn) Add adapter-level fitness function caching (cache_evaluation_storage): - \"memory\": in-memory dict, lost on restart - \"disk\": pickle files in {run_dir}/fitness_cache/, persists across runs - \"auto\": uses disk if run_dir provided, else memory Files changed: - src/gepa/optimize_anything.py: add CacheEvaluationStorage type, resolve cache mode - optimize_anything_adapter.py: implement caching with thread-safe storage - examples/circle_packing_refiner/: update to use new parameter names - tests/: add test_best_example_evals.py and test_cache_evaluation_storage.py * Simplify RefinerConfig API and improve defaults RefinerConfig: - Remove refiner_prompt (use DEFAULT_REFINER_PROMPT or candidate's prompt) - Remove min_refinements and stop_when - Refinement now runs at least once, stops when no improvement - Default max_refinements = 2 ReflectionConfig: - reflection_minibatch_size defaults to 1 for single-instance mode (dataset=None), 3 otherwise EngineConfig: - best_example_evals_k default = 30 Also surface refiner's multiple metrics (max_score, mean_score, ema_score_fixed, ema_score_adaptive) to objective scores output. * Simplify kernelbench example to use RefinerConfig - Replace manual PromptCache and StateTracker with adapter-based caching - Replace manual refinement loop with RefinerConfig (adapter handles it) - Reduce main.py from 636 to 236 lines (~63% reduction) - Remove RefinerSig from prompts.py (adapter uses DEFAULT_REFINER_PROMPT) - Add run_with_GPUs.py locally instead of importing from parent - Remove docs/ and tests/ directories (outdated after refactor) The simplified version uses: - cache_evaluation=True in EngineConfig for automatic caching - RefinerConfig with max_refinements for automatic refinement - Single-component seed (kernel_gen_prompt only) * Remove old arc_agi and circle_packing examples These are replaced by circle_packing_refiner which uses RefinerConfig. * Update circle_packing_refiner example - Use lowercase \"scores\" key for multi-objective support - Add log directory cleanup on startup - Remove max_refinements override (use default) - Add timeout constraint to BACKGROUND prompt - Comment out debug prints * Refactor adapter and add max_candidate_proposals stopper optimize_anything_adapter.py: - Extract _get_target_param() to avoid code duplication - Consolidate parallel evaluation into _run_parallel() helper - Remove unused _format_evaluation_feedback() method optimize_anything.py: - Add max_candidate_proposals to EngineConfig as stopping condition * Add RefinerConfig tests and ignore outputs/ tests/test_refiner.py: Test suite for RefinerConfig using number guessing scenario - validates caching (memory/disk) and refinement functionality. * Rename arc_agi_poetiq to arc_agi and circle_packing_refiner to circle_packing * Fix arc_agi imports and output paths after rename * Simplify arc_agi and kernelbench examples arc_agi: - Consolidate prompts, dataset loading, TrackedLLM into utils.py - Remove unused __init__.py, cache.py, tracked_llm.py - Remove test files (tests/) kernelbench: - Inline fitness_fn in main.py with run_kernel() and build_side_info() helpers - Remove GPU locking infrastructure (run_with_GPUs.py, GPUManager) - Use simple nvidia-smi polling for sequential execution - Move constants (LLM, TIMEOUT) to prompts.py - Remove argparse, use constants for config * Simplify polynomial example - Consolidate config.py, evaluator.py, prompt.py into main.py - Use constants instead of argparse - Use best_example_evals for warm-start trajectory - Return all_attempts list for trajectory tracking - Clean helpers: execute_code, extract_best_xs, build_side_info * Simplify adrs fitness_fn to return (score, side_info) Remove output from return tuple to match optimize_anything API. Output code is commented out rather than deleted. * Simplify aime_math and circle_packing fitness_fn - aime_math: return (score, side_info) and clean up config defaults - circle_packing: remove debug comments * Fix track_best_outputs by using side_infos instead of None outputs The fitness_fn wrapper normalizes returns to (score, None, side_info), so extracting the middle element always yielded None, which was filtered out by the `output is not None` guard in _update_pareto_front_for_val_id. Use the already-computed side_infos list instead. * Enable refiner by default and refine all params as JSON dict - RefinerConfig enabled by default (set refiner=None to disable) - refiner_lm defaults to reflection_lm when not specified - Auto-inject refiner_prompt into seed candidates - Refiner now refines all non-refiner params together as a JSON dict instead of a single target param - Side info uses best attempt's structure with refiner_prompt_specific_info containing refinement_rate scores - Default reflection_lm to openai/gpt-5.1, use_cloudpickle to True - Add refiner=None to existing tests that don't test refiner - Add new tests: multi-param, dataset mode, frontier types, side_info structure * Update examples to match latest API and remove redundant configs - optimize_linear_function_params: rewrite from old batch API to single-example 2-tuple signature (example, **kwargs) -> (score, side_info) - circle_packing, kernelbench: remove redundant refiner_lm (defaults to reflection_lm now) - adrs/can_be_late, adrs/cloudcast: remove redundant seed=0 and skip_perfect_score=False (already the defaults) - polynomial: add max_candidate_proposals=20 to fix missing stopping condition that would raise ValueError at runtime * Add polynomial utils and update blogpost notebook - Extract polynomial helpers into examples/polynomial/utils.py - Update optimize_anything_blogpost notebook * Fix refiner side_info to show original evaluation for reflection Use original (unrefined) side_info as base so reflection LLM sees raw candidate quality. Replace refinement_rate metrics with actual best scores from refinement attempts. Add full attempt history for refiner_prompt reflection. * Remove verbose refiner print from optimize_anything_adapter * Remove redirect_stdout from fitness_fn wrapper to fix swallowed prints redirect_stdout is not thread-safe and was silently capturing all print output from fitness functions when running with parallel=True, causing logs to be lost. * Add kwargs filtering to fitness_fn wrapper and smoke test script Inspect fitness_fn signature at wrap time to only forward kwargs it accepts (e.g. best_example_evals). Pass example as keyword arg instead of positional to support both `def fn(candidate, example)` and `def fn(candidate, **kwargs)` patterns. Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com> * Disable refiner by default for examples that don't use it Set refiner=None in arc_agi, aime_math, cloudcast, can_be_late, and linear examples since RefinerConfig is now enabled by default. Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com> * Fix refiner LM to use dspy.LM instead of litellm wrapper The refiner requires a dspy.BaseLM instance (used via dspy.context(lm=...)), not a plain callable. Also fix ordering so refiner_lm defaults to reflection_lm string before reflection_lm is converted to a callable. Failed refiner attempts now correctly score 0.0 instead of original_score. Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com> * Add more info to cloudcast * Change cloudcast * Correct notebook * Correct cloudcast * Create diagram * Update to fix CI * Change output format to (score, best_candidate, side_info) tuple - evaluate() now returns outputs as list of (score, best_candidate, side_info) tuples - Without refiner: best_candidate = original candidate - With refiner: best_candidate = winning candidate (original or refined) - _refine_and_evaluate tracks best_candidate dict instead of best_output - trajectories unchanged (still contains side_info for reflection) * Make refiner disabled by default, explicitly enable in examples - Change GEPAConfig.refiner default from RefinerConfig() to None - Change RefinerConfig.max_refinements default from 2 to 1 - Update circle_packing and kernelbench examples to explicitly enable refiner * Migrate refiner from DSPy to LiteLLM for consistency with reflection Remove DSPy dependency for refiner - now uses litellm.completion() directly like reflection_lm. Add REFINER_PROMPT_TEMPLATE constant to format prompts. * Make cloudpickle usage configurable via EngineConfig.use_cloudpickle Add set_use_cloudpickle() to code_execution.py and call it from optimize_anything.py based on config. Allows fallback to standard pickle when cloudpickle isn't needed or causes issues. * Remove verbose print statements from refiner logic Refiner now runs silently without printing iteration details, JSON proposals, or score comparisons to stdout. * Make API Changes * Remove merge * Extract stdio * Migrate cache config * Add tests * Wrapper context manager * Add fixes * Fixes * Fix * Fixes * Typing * iUpdate cloudcast image * Fixes * Fix refiner: remove dead DSPy references, fix scoring for failed attempts - Remove _initialize_refiner() and refiner_predictor (migrated to LiteLLM) - Remove dead `import dspy` that would fail in CI - Filter out failed attempts (no side_info) when picking best refined score - Fix Ruff: import ordering, unused `import sys`, missing strict=False - Use FitnessFn type alias instead of raw Callable * Only include refiner scores when user's side_info has scores Avoids injecting empty \"scores\" into refiner_prompt_specific_info when the user isn't using objective frontier. * Fix evaluator diagnostics on exception and conditional refiner scores Preserve oa.log()/stdout/stderr when evaluator raises instead of discarding them. Only inject \"scores\" in refiner side_info when user's side_info uses objective frontier. * Revert \"Only include refiner scores when user's side_info has scores\" This reverts commit b8b019e884597646ac7459d86270d2fd3f80e8c9. * Revert \"Fix refiner: remove dead DSPy references, fix scoring for failed attempts\" This reverts commit dda7d792b977da5c2874685f3d3c59bbad5d838f. * Trigger CI * Initialize result before try to satisfy Pyright * Fix Pyright return type inference for failure path * Use 0.0 for failure score to match codebase convention * Use isinstance check instead of separate exc variable for Pyright * Update the examples to the latest codes * Respect raise_on_exception in EvaluatorWrapper, update examples to use OptimizationState - Thread raise_on_exception from EngineConfig into EvaluatorWrapper so exceptions propagate when configured instead of being silently absorbed - Move assert callable(refiner_lm) before refinement loop to fail fast - Update circle_packing and polynomial examples to use opt_state parameter - Move extract helpers into respective utils modules * Address luke feedback * Add Image Side info * Add pelican example * Fixes * Add docs * Remove files excluded from PR: examples/, assets/blog/, blogpost, diagram, test script, gitmodules Excluded from optimize_anything_pr branch: - examples/* (all example code and data) - assets/blog/* (blog-related images) - optimize_anything_blogpost.ipynb - optimize_anything_diagram_v2.html - scripts/test_all_examples.py - .gitmodules - .gitignore (restored to main version) Co-authored-by: Cursor <cursoragent@cursor.com> * Add optimize_anything to public API * Change 0 to -1e9 * Fix * Ruff * Add optimize_anything to public API * Fix * Ruff * Ad ddocs * Revert multi seed --------- Co-authored-by: Lakshya A Agrawal <lakshyaaagrawal@berkeley.edu> Co-authored-by: Donghyun Lee <lukeleeai@gmail.com> Co-authored-by: Shangyin Tan <shangyin@berkeley.edu> Co-authored-by: Wenjie Ma <windsey@berkeley.edu> Co-authored-by: Karim Elmaaroufi <k.e@berkeley.edu> Co-authored-by: Wenjie Ma <windsey@berkeley.edu> Co-authored-by: Claude Opus 4.6 <noreply@anthropic.com> Co-authored-by: Cursor <cursoragent@cursor.com>")[#204](https://github.com/gepa-ai/gepa/pull/204)[)](https://github.com/gepa-ai/gepa/commit/b2b613ea189e72867d085b93614b3e626e4ccd8b "Add `optimize_anything`: unified high-level API for GEPA (#204) * v0 * Add working optimize_anything api * Fix type errors * Update uv.lock * ruff fix * Fix tests * Fix typo * Add custom instruction proposer * Add custom instruction proposer * Move towards custom instruction proposers * Fix test * Fix typing * Implement multi-objective scores * Improve template * Adding a polynomial minimization example * Adding a polynomial minimization example * Add a simple readme for the polynomial example * Add details on the polynomial example readme * Add logic for counting the number of evaluation calls * Add arc-agi and circle packing into examples * Add math prompt optimization example * Add optimize anything blogpost notebook * Refactored the math prompt optimization example * refactor arc_agi example * Refactored ARC-AGI example * Add minimal notebook blogs (WIP) * Incorporated minimal code examples (prompt + agent) into the main blog notebook * Incorporated minimal code examples (prompt + agent) into the main blog notebook * Add figures for blog * fitness_fn is now scalar * Update the arc agi prompt to be compatible with optimize_anything api * Add aime + arc agi plots for blog * Add aime + arc agi plots for blog * Minor change in notebook * Add polynomial grah * Minor * Add new blog figures (aime, arc agi, polynomial, and circle packing (26)) * Add new blog figures (aime, arc agi, polynomial, and circle packing (26)) * Add the best program example to the blog * Update the intro of the blog by adding a brief problem desc and restructuring the abstract * Update the blog: simplyfing the demo code * Update blog * Update the circle packing example code to use a refiner prompt evolution * Add objective and background * Add cant_be_late for ADRS example * Make dataset optional * Add common code execution utils * Update the blog * Add evaluation_cache to optimize_anything.py * Pass example as kwarg to support dataset=None mode; Handle EOFError when subprocess crashes before writing results for code_execution.py * Fix subprocess pickle errors: filter non-picklable objects, handle empty results * Add README for ADRS example * Remove old wandb * Add requirements for simulators * Ruff * Add all the latest examples codes into the blog notebook * Add the latest experiments results (aime, circle packing 26, and polynomial) into the blog folder * Add latest blog experiment results * Add kernelbench and the latest codes for the blog * Add blog experimnets outputs inside examples * Add cloudcast example * Add ADRS examples and blogpost * Update can't be late plots * Update noteboook * Delete print statement in these examples * Update cloudcast results * Add refiner * Add latest plots from kernel bench and arc agi * git commit -m \"Add RefinerConfig enhancements and example_best_evals warm-start system RefinerConfig improvements: - Add min_refinements to guarantee minimum refinement iterations - Add stop_when for conditional early stopping based on side_info keys - Pass full attempt history to refiner LLM for context - Add DEFAULT_REFINER_PROMPT with {objective}/{background} placeholders - Remove \"stop on no improvement\" default (now runs max_refinements) Warm-start support: - Add example_best_evals_k to EngineConfig (default 10) - Track top-K evaluations per example with thread-safe access - Pass example_best_evals to fitness_fn for warm-start optimization New example: - Add circle_packing_refiner using simplified RefinerConfig API\" error: pathspec 'on' did not match any file(s) known to git error: pathspec 'no' did not match any file(s) known to git error: pathspec 'improvement default (now runs max_refinements) Warm-start support: - Add example_best_evals_k to EngineConfig (default 10) - Track top-K evaluations per example with thread-safe access - Pass example_best_evals to fitness_fn for warm-start optimization New example: - Add circle_packing_refiner using simplified RefinerConfig API' did not match any file(s) known to git * Rename example_best_evals to best_example_evals and add cache_evaluation_storage Parameter renaming for clarity: - example_best_evals_k → best_example_evals_k (in EngineConfig) - example_best_evals → best_example_evals (passed to fitness_fn) Add adapter-level fitness function caching (cache_evaluation_storage): - \"memory\": in-memory dict, lost on restart - \"disk\": pickle files in {run_dir}/fitness_cache/, persists across runs - \"auto\": uses disk if run_dir provided, else memory Files changed: - src/gepa/optimize_anything.py: add CacheEvaluationStorage type, resolve cache mode - optimize_anything_adapter.py: implement caching with thread-safe storage - examples/circle_packing_refiner/: update to use new parameter names - tests/: add test_best_example_evals.py and test_cache_evaluation_storage.py * Simplify RefinerConfig API and improve defaults RefinerConfig: - Remove refiner_prompt (use DEFAULT_REFINER_PROMPT or candidate's prompt) - Remove min_refinements and stop_when - Refinement now runs at least once, stops when no improvement - Default max_refinements = 2 ReflectionConfig: - reflection_minibatch_size defaults to 1 for single-instance mode (dataset=None), 3 otherwise EngineConfig: - best_example_evals_k default = 30 Also surface refiner's multiple metrics (max_score, mean_score, ema_score_fixed, ema_score_adaptive) to objective scores output. * Simplify kernelbench example to use RefinerConfig - Replace manual PromptCache and StateTracker with adapter-based caching - Replace manual refinement loop with RefinerConfig (adapter handles it) - Reduce main.py from 636 to 236 lines (~63% reduction) - Remove RefinerSig from prompts.py (adapter uses DEFAULT_REFINER_PROMPT) - Add run_with_GPUs.py locally instead of importing from parent - Remove docs/ and tests/ directories (outdated after refactor) The simplified version uses: - cache_evaluation=True in EngineConfig for automatic caching - RefinerConfig with max_refinements for automatic refinement - Single-component seed (kernel_gen_prompt only) * Remove old arc_agi and circle_packing examples These are replaced by circle_packing_refiner which uses RefinerConfig. * Update circle_packing_refiner example - Use lowercase \"scores\" key for multi-objective support - Add log directory cleanup on startup - Remove max_refinements override (use default) - Add timeout constraint to BACKGROUND prompt - Comment out debug prints * Refactor adapter and add max_candidate_proposals stopper optimize_anything_adapter.py: - Extract _get_target_param() to avoid code duplication - Consolidate parallel evaluation into _run_parallel() helper - Remove unused _format_evaluation_feedback() method optimize_anything.py: - Add max_candidate_proposals to EngineConfig as stopping condition * Add RefinerConfig tests and ignore outputs/ tests/test_refiner.py: Test suite for RefinerConfig using number guessing scenario - validates caching (memory/disk) and refinement functionality. * Rename arc_agi_poetiq to arc_agi and circle_packing_refiner to circle_packing * Fix arc_agi imports and output paths after rename * Simplify arc_agi and kernelbench examples arc_agi: - Consolidate prompts, dataset loading, TrackedLLM into utils.py - Remove unused __init__.py, cache.py, tracked_llm.py - Remove test files (tests/) kernelbench: - Inline fitness_fn in main.py with run_kernel() and build_side_info() helpers - Remove GPU locking infrastructure (run_with_GPUs.py, GPUManager) - Use simple nvidia-smi polling for sequential execution - Move constants (LLM, TIMEOUT) to prompts.py - Remove argparse, use constants for config * Simplify polynomial example - Consolidate config.py, evaluator.py, prompt.py into main.py - Use constants instead of argparse - Use best_example_evals for warm-start trajectory - Return all_attempts list for trajectory tracking - Clean helpers: execute_code, extract_best_xs, build_side_info * Simplify adrs fitness_fn to return (score, side_info) Remove output from return tuple to match optimize_anything API. Output code is commented out rather than deleted. * Simplify aime_math and circle_packing fitness_fn - aime_math: return (score, side_info) and clean up config defaults - circle_packing: remove debug comments * Fix track_best_outputs by using side_infos instead of None outputs The fitness_fn wrapper normalizes returns to (score, None, side_info), so extracting the middle element always yielded None, which was filtered out by the `output is not None` guard in _update_pareto_front_for_val_id. Use the already-computed side_infos list instead. * Enable refiner by default and refine all params as JSON dict - RefinerConfig enabled by default (set refiner=None to disable) - refiner_lm defaults to reflection_lm when not specified - Auto-inject refiner_prompt into seed candidates - Refiner now refines all non-refiner params together as a JSON dict instead of a single target param - Side info uses best attempt's structure with refiner_prompt_specific_info containing refinement_rate scores - Default reflection_lm to openai/gpt-5.1, use_cloudpickle to True - Add refiner=None to existing tests that don't test refiner - Add new tests: multi-param, dataset mode, frontier types, side_info structure * Update examples to match latest API and remove redundant configs - optimize_linear_function_params: rewrite from old batch API to single-example 2-tuple signature (example, **kwargs) -> (score, side_info) - circle_packing, kernelbench: remove redundant refiner_lm (defaults to reflection_lm now) - adrs/can_be_late, adrs/cloudcast: remove redundant seed=0 and skip_perfect_score=False (already the defaults) - polynomial: add max_candidate_proposals=20 to fix missing stopping condition that would raise ValueError at runtime * Add polynomial utils and update blogpost notebook - Extract polynomial helpers into examples/polynomial/utils.py - Update optimize_anything_blogpost notebook * Fix refiner side_info to show original evaluation for reflection Use original (unrefined) side_info as base so reflection LLM sees raw candidate quality. Replace refinement_rate metrics with actual best scores from refinement attempts. Add full attempt history for refiner_prompt reflection. * Remove verbose refiner print from optimize_anything_adapter * Remove redirect_stdout from fitness_fn wrapper to fix swallowed prints redirect_stdout is not thread-safe and was silently capturing all print output from fitness functions when running with parallel=True, causing logs to be lost. * Add kwargs filtering to fitness_fn wrapper and smoke test script Inspect fitness_fn signature at wrap time to only forward kwargs it accepts (e.g. best_example_evals). Pass example as keyword arg instead of positional to support both `def fn(candidate, example)` and `def fn(candidate, **kwargs)` patterns. Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com> * Disable refiner by default for examples that don't use it Set refiner=None in arc_agi, aime_math, cloudcast, can_be_late, and linear examples since RefinerConfig is now enabled by default. Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com> * Fix refiner LM to use dspy.LM instead of litellm wrapper The refiner requires a dspy.BaseLM instance (used via dspy.context(lm=...)), not a plain callable. Also fix ordering so refiner_lm defaults to reflection_lm string before reflection_lm is converted to a callable. Failed refiner attempts now correctly score 0.0 instead of original_score. Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com> * Add more info to cloudcast * Change cloudcast * Correct notebook * Correct cloudcast * Create diagram * Update to fix CI * Change output format to (score, best_candidate, side_info) tuple - evaluate() now returns outputs as list of (score, best_candidate, side_info) tuples - Without refiner: best_candidate = original candidate - With refiner: best_candidate = winning candidate (original or refined) - _refine_and_evaluate tracks best_candidate dict instead of best_output - trajectories unchanged (still contains side_info for reflection) * Make refiner disabled by default, explicitly enable in examples - Change GEPAConfig.refiner default from RefinerConfig() to None - Change RefinerConfig.max_refinements default from 2 to 1 - Update circle_packing and kernelbench examples to explicitly enable refiner * Migrate refiner from DSPy to LiteLLM for consistency with reflection Remove DSPy dependency for refiner - now uses litellm.completion() directly like reflection_lm. Add REFINER_PROMPT_TEMPLATE constant to format prompts. * Make cloudpickle usage configurable via EngineConfig.use_cloudpickle Add set_use_cloudpickle() to code_execution.py and call it from optimize_anything.py based on config. Allows fallback to standard pickle when cloudpickle isn't needed or causes issues. * Remove verbose print statements from refiner logic Refiner now runs silently without printing iteration details, JSON proposals, or score comparisons to stdout. * Make API Changes * Remove merge * Extract stdio * Migrate cache config * Add tests * Wrapper context manager * Add fixes * Fixes * Fix * Fixes * Typing * iUpdate cloudcast image * Fixes * Fix refiner: remove dead DSPy references, fix scoring for failed attempts - Remove _initialize_refiner() and refiner_predictor (migrated to LiteLLM) - Remove dead `import dspy` that would fail in CI - Filter out failed attempts (no side_info) when picking best refined score - Fix Ruff: import ordering, unused `import sys`, missing strict=False - Use FitnessFn type alias instead of raw Callable * Only include refiner scores when user's side_info has scores Avoids injecting empty \"scores\" into refiner_prompt_specific_info when the user isn't using objective frontier. * Fix evaluator diagnostics on exception and conditional refiner scores Preserve oa.log()/stdout/stderr when evaluator raises instead of discarding them. Only inject \"scores\" in refiner side_info when user's side_info uses objective frontier. * Revert \"Only include refiner scores when user's side_info has scores\" This reverts commit b8b019e884597646ac7459d86270d2fd3f80e8c9. * Revert \"Fix refiner: remove dead DSPy references, fix scoring for failed attempts\" This reverts commit dda7d792b977da5c2874685f3d3c59bbad5d838f. * Trigger CI * Initialize result before try to satisfy Pyright * Fix Pyright return type inference for failure path * Use 0.0 for failure score to match codebase convention * Use isinstance check instead of separate exc variable for Pyright * Update the examples to the latest codes * Respect raise_on_exception in EvaluatorWrapper, update examples to use OptimizationState - Thread raise_on_exception from EngineConfig into EvaluatorWrapper so exceptions propagate when configured instead of being silently absorbed - Move assert callable(refiner_lm) before refinement loop to fail fast - Update circle_packing and polynomial examples to use opt_state parameter - Move extract helpers into respective utils modules * Address luke feedback * Add Image Side info * Add pelican example * Fixes * Add docs * Remove files excluded from PR: examples/, assets/blog/, blogpost, diagram, test script, gitmodules Excluded from optimize_anything_pr branch: - examples/* (all example code and data) - assets/blog/* (blog-related images) - optimize_anything_blogpost.ipynb - optimize_anything_diagram_v2.html - scripts/test_all_examples.py - .gitmodules - .gitignore (restored to main version) Co-authored-by: Cursor <cursoragent@cursor.com> * Add optimize_anything to public API * Change 0 to -1e9 * Fix * Ruff * Add optimize_anything to public API * Fix * Ruff * Ad ddocs * Revert multi seed --------- Co-authored-by: Lakshya A Agrawal <lakshyaaagrawal@berkeley.edu> Co-authored-by: Donghyun Lee <lukeleeai@gmail.com> Co-authored-by: Shangyin Tan <shangyin@berkeley.edu> Co-authored-by: Wenjie Ma <windsey@berkeley.edu> Co-authored-by: Karim Elmaaroufi <k.e@berkeley.edu> Co-authored-by: Wenjie Ma <windsey@berkeley.edu> Co-authored-by: Claude Opus 4.6 <noreply@anthropic.com> Co-authored-by: Cursor <cursoragent@cursor.com>") | Feb 14, 2026 |
| View all files |
## Repository files navigation
* [README](https://github.com/gepa-ai/gepa#)
* [Contributing](https://github.com/gepa-ai/gepa#)
* [MIT license](https://github.com/gepa-ai/gepa#)
[](https://raw.githubusercontent.com/gepa-ai/gepa/refs/heads/main/docs/docs/assets/gepa_logo_with_text.svg)
**Optimize any text parameter — prompts, code, agent architectures, configurations — using LLM-based reflection and Pareto-efficient evolutionary search.**
[**Website**](https://gepa-ai.github.io/gepa/) | [**Quick Start**](https://gepa-ai.github.io/gepa/guides/quickstart/) | [**Paper**](https://arxiv.org/abs/2507.19457) | [**Blog**](https://gepa-ai.github.io/gepa/blog/) | [**Discord**](https://discord.gg/WXFSeVGdbW)
[](https://pypi.org/project/gepa/)[](https://pepy.tech/projects/gepa)[](https://github.com/gepa-ai/gepa)[](https://opensource.org/licenses/MIT)
[](https://join.slack.com/t/gepa-ai/shared_invite/zt-3o352xhyf-QZDfwmMpiQjsvoSYo7M1_w)[](https://discord.gg/WXFSeVGdbW)
* * *
## What is GEPA?
[](https://github.com/gepa-ai/gepa#what-is-gepa)
**GEPA** (Genetic-Pareto) is a framework for optimizing any system with textual parameters against any evaluation metric. Unlike RL or gradient-based methods that collapse execution traces into a single scalar reward, GEPA uses LLMs to _read_ full execution traces — error messages, profiling data, reasoning logs — to diagnose _why_ a candidate failed and propose targeted fixes. Through iterative reflection, mutation, and Pareto-aware selection, GEPA evolves high-performing variants with minimal evaluations.
**If you can measure it, you can optimize it**: prompts, code, agent architectures, scheduling policies, vector graphics, and more.
### Key Results
[](https://github.com/gepa-ai/gepa#key-results)
| | |
| --- | --- |
| **90x cheaper** | Open-source models + GEPA beat Claude Opus 4.1 at [Databricks](https://www.databricks.com/blog/building-state-art-enterprise-agents-90x-cheaper-automated-prompt-optimization) |
| **35x faster than RL** | 100–500 evaluations vs. 5,000–25,000+ for GRPO ([paper](https://arxiv.org/abs/2507.19457)) |
| **32% → 89%** | ARC-AGI agent accuracy via [architecture discovery](https://gepa-ai.github.io/gepa/blog/introducing-optimize-anything/#5-agent-architecture-discovery) |
| **40.2% cost savings** | Cloud scheduling policy [discovered by GEPA](https://gepa-ai.github.io/gepa/blog/introducing-optimize-anything/#3-systems-research), beating expert heuristics |
| **55% → 82%** | Coding agent resolve rate on Jinja via [auto-learned skills](https://gepa-ai.github.io/gepa/blog/automatically-learning-skills-for-coding-agents/) |
| **50+ production uses** | Across Shopify, Databricks, Dropbox, OpenAI, Pydantic, MLflow, Comet ML, and [more](https://gepa-ai.github.io/gepa/guides/use-cases/) |
> _"Both DSPy and (especially) **GEPA are currently severely under hyped** in the AI context engineering world"_ — **Tobi Lutke**, CEO, Shopify
* * *
## Installation
[](https://github.com/gepa-ai/gepa#installation)
undefinedshell
pip install gepa
undefined
To install the latest from `main`:
undefinedshell
pip install git+https://github.com/gepa-ai/gepa.git
undefined
* * *
## Quick Start
[](https://github.com/gepa-ai/gepa#quick-start)
### Simple Prompt Optimization
[](https://github.com/gepa-ai/gepa#simple-prompt-optimization)
Optimize a system prompt for math problems from the AIME benchmark in a few lines of code ([full tutorial](https://dspy.ai/tutorials/gepa_aime/)):
undefinedpython
import gepa
trainset, valset, _ = gepa.examples.aime.init_dataset()
seed_prompt = {
"system_prompt": "You are a helpful assistant. Answer the question. "
"Put your final answer in the format '### <answer>'"
}
result = gepa.optimize(
seed_candidate=seed_prompt,
trainset=trainset,
valset=valset,
task_lm="openai/gpt-4.1-mini",
max_metric_calls=150,
reflection_lm="openai/gpt-5",
)
print("Optimized prompt:", result.best_candidate['system_prompt'])
undefined
**Result:** GPT-4.1 Mini goes from 46.6% → 56.6% on AIME 2025 (+10 percentage points).
### With DSPy (Recommended for AI Pipelines)
[](https://github.com/gepa-ai/gepa#with-dspy-recommended-for-ai-pipelines)
The most powerful way to use GEPA for prompt optimization is within [DSPy](https://dspy.ai/), where it's available as `dspy.GEPA`. See [dspy.GEPA tutorials](https://dspy.ai/tutorials/gepa_ai_program/) for executable notebooks.
undefinedpython
import dspy
optimizer = dspy.GEPA(
metric=your_metric,
max_metric_calls=150,
reflection_lm="openai/gpt-5",
)
optimized_program = optimizer.compile(student=MyProgram(), trainset=trainset, valset=valset)
undefined
### optimize_anything: Beyond Prompts
[](https://github.com/gepa-ai/gepa#optimize_anything-beyond-prompts)
The [`optimize_anything`](https://gepa-ai.github.io/gepa/blog/introducing-optimize-anything/) API optimizes _any_ text artifact — code, agent architectures, configurations, SVGs — not just prompts. You provide an evaluator; the system handles the search.
undefinedpython
import gepa.optimize_anything as oa
from gepa.optimize_anything import optimize_anything, GEPAConfig, EngineConfig
def evaluate(candidate: str) -> float:
result = run_my_system(candidate)
oa.log(f"Output: {result.output}") # Actionable Side Information
oa.log(f"Error: {result.error}") # feeds back into reflection
return result.score
result = optimize_anything(
seed_candidate="<your initial artifact>",
evaluator=evaluate,
objective="Describe what you want to optimize for.",
config=GEPAConfig(engine=EngineConfig(max_metric_calls=100)),
)
undefined
* * *
## How It Works
[](https://github.com/gepa-ai/gepa#how-it-works)
Traditional optimizers know _that_ a candidate failed but not _why_. GEPA takes a different approach:
1. **Select** a candidate from the Pareto frontier (candidates excelling on different task subsets)
2. **Execute** on a minibatch, capturing full execution traces
3. **Reflect** — an LLM reads the traces (error messages, profiler output, reasoning logs) and diagnoses failures
4. **Mutate** — generate an improved candidate informed by accumulated lessons from all ancestors
5. **Accept** — add to the pool if improved, update the Pareto front
GEPA also supports **system-aware merge** — combining strengths of two Pareto-optimal candidates excelling on different tasks. The key concept is **Actionable Side Information (ASI)**: diagnostic feedback returned by evaluators that serves as the text-optimization analogue of a gradient.
For details, see the [paper](https://arxiv.org/abs/2507.19457) and the [documentation](https://gepa-ai.github.io/gepa/guides/).
* * *
## Adapters: Plug GEPA into Any System
[](https://github.com/gepa-ai/gepa#adapters-plug-gepa-into-any-system)
GEPA connects to your system via the [`GEPAAdapter`](https://github.com/gepa-ai/gepa/blob/main/src/gepa/core/adapter.py) interface — implement `evaluate` and `make_reflective_dataset`, and GEPA handles the rest.
**Built-in adapters:**
| Adapter | Description |
| --- | --- |
| [DefaultAdapter](https://github.com/gepa-ai/gepa/blob/main/src/gepa/adapters/default_adapter) | System prompt optimization for single-turn LLM tasks |
| [ConfidenceAdapter](https://github.com/gepa-ai/gepa/blob/main/src/gepa/adapters/confidence_adapter) | Logprob-aware classification optimization — penalizes lucky guesses and feeds confidence diagnostics into reflection. `pip install "gepa[confidence]"` |
| [DSPy Full Program](https://github.com/gepa-ai/gepa/blob/main/src/gepa/adapters/dspy_full_program_adapter) | Evolves entire DSPy programs (signatures, modules, control flow). **67% → 93%** on MATH. |
| [Generic RAG](https://github.com/gepa-ai/gepa/blob/main/src/gepa/adapters/generic_rag_adapter) | Vector store-agnostic RAG optimization (ChromaDB, Weaviate, Qdrant, Pinecone) |
| [MCP Adapter](https://github.com/gepa-ai/gepa/blob/main/src/gepa/adapters/mcp_adapter) | Optimize [MCP](https://modelcontextprotocol.io/) tool descriptions and system prompts |
| [TerminalBench](https://github.com/gepa-ai/gepa/blob/main/src/gepa/adapters/terminal_bench_adapter) | Optimize the [Terminus](https://www.tbench.ai/terminus) terminal-use agent |
| [AnyMaths](https://github.com/gepa-ai/gepa/blob/main/src/gepa/adapters/anymaths_adapter) | Mathematical problem-solving and reasoning tasks |
See the [adapters guide](https://gepa-ai.github.io/gepa/guides/adapters/) for how to build your own, and [DSPy's adapter](https://github.com/stanfordnlp/dspy/tree/main/dspy/teleprompt/gepa/gepa_utils.py) as a reference.
* * *
## Integrations
[](https://github.com/gepa-ai/gepa#integrations)
GEPA is integrated into several major frameworks:
* **[DSPy](https://dspy.ai/)** — `dspy.GEPA` for optimizing DSPy programs. [Tutorials](https://dspy.ai/tutorials/gepa_ai_program/).
* **[MLflow](https://mlflow.org/docs/latest/genai/prompt-registry/optimize-prompts/)** — `mlflow.genai.optimize_prompts()` for automatic prompt improvement.
* **[Comet ML Opik](https://www.comet.com/docs/opik/agent_optimization/algorithms/gepa_optimizer)** — Core optimization algorithm in Opik Agent Optimizer.
* **[Pydantic](https://pydantic.dev/articles/prompt-optimization-with-gepa)** — Prompt optimization for Pydantic AI.
* **[OpenAI Cookbook](https://cookbook.openai.com/examples/partners/self_evolving_agents/autonomous_agent_retraining)** — Self-evolving agents with GEPA.
* **[HuggingFace Cookbook](https://huggingface.co/learn/cookbook/en/dspy_gepa)** — Prompt optimization guide.
* **[Google ADK](https://adk.dev/optimize/)** — Built-in agent optimization in Google's Agent Development Kit. [Community tutorial](https://raphaelmansuy.github.io/adk_training/blog/gepa-optimization-tutorial/).
* * *
## Example Optimized Prompts
[](https://github.com/gepa-ai/gepa#example-optimized-prompts)
GEPA can be thought of as precomputing reasoning during optimization to produce a plan for future task instances. Here are examples of the detailed prompts GEPA discovers:
Example GEPA Prompts
HotpotQA (multi-hop QA) Prompt AIME Prompt
[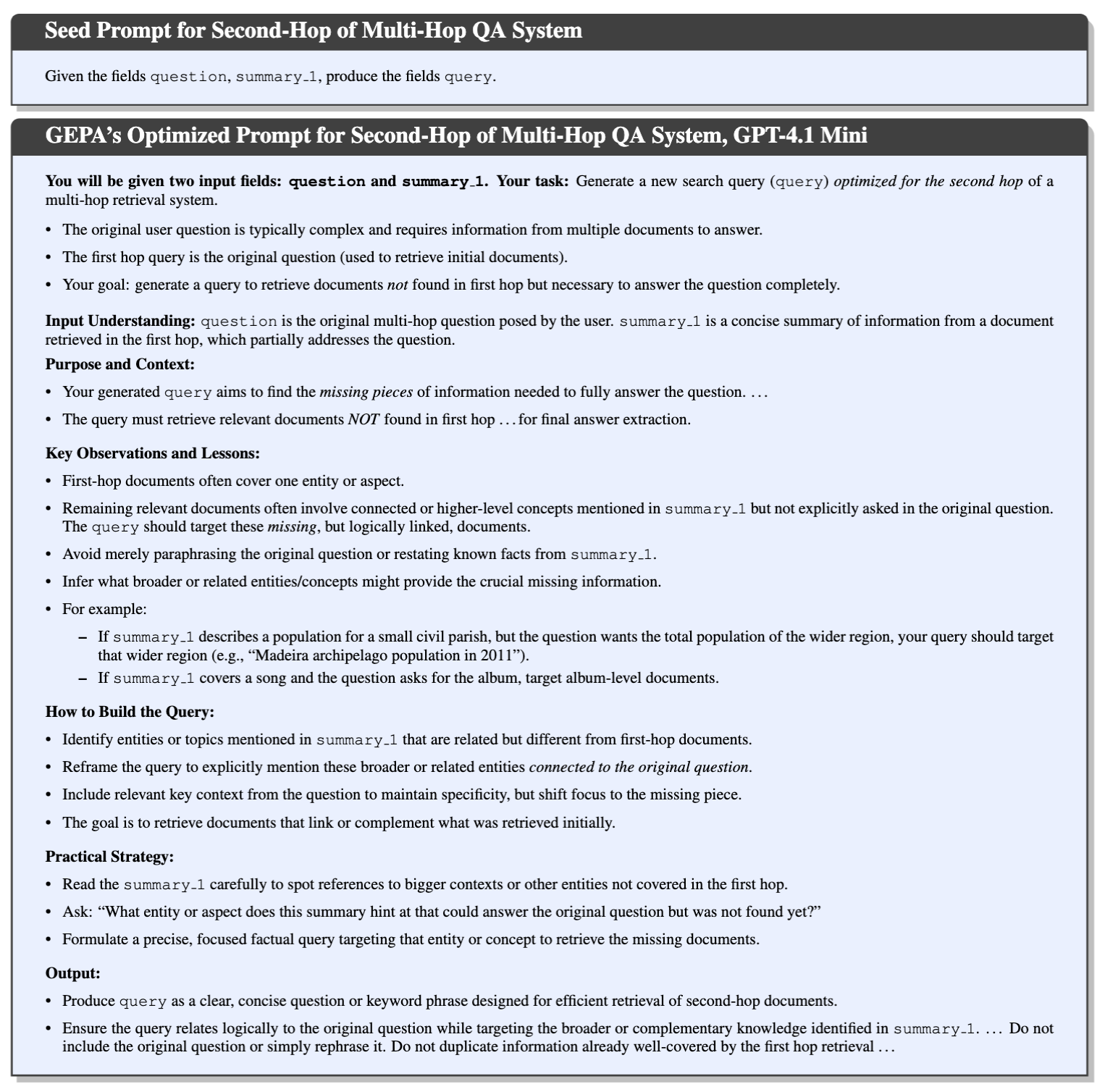](https://raw.githubusercontent.com/gepa-ai/gepa/refs/heads/main/assets/gepa_prompt_hotpotqa.png)
Click to view full HotpotQA prompt[HotpotQA Prompt Begin]
You will be given two input fields: `question` and `summary_1`.
Your task is to generate a new search query (`query`) optimized for the **second hop** of a multi-hop retrieval system. The original user question is typically complex and requires information from multiple documents to answer. The first hop query is the original question used to retrieve an initial set of documents. Your goal is to generate a **second hop query** that retrieves _additional relevant documents_ that were _not_ found in the first hop but are necessary to answer the original question completely.
Detailed task instructions and hints:
1. **Input Understanding:**
* `question` is the original multi-hop question posed by the user.
* `summary_1` is a concise summary of information from a document retrieved in the first hop, which partially addresses the question.
2. **Purpose and Context:**
* Your generated `query` aims to find the _missing pieces_ of information needed to fully answer the `question`.
* The multi-hop retrieval system works in stages:
* First hop: The original question returns some documents.
* Second hop: Your query must help retrieve any _other relevant documents_ NOT found in the first hop that hold complementary or broader context necessary for final answer extraction.
3. **Key Observations from Examples and Feedback:**
* First-hop documents often cover one entity or aspect in the question.
* Remaining relevant documents often involve connected or higher-level concepts mentioned in `summary_1` but not explicitly asked in the original question.
* The `query` should be formulated to explicitly target these _missing_, but logically linked, documents.
* Avoid merely paraphrasing the original question or restating known facts from `summary_1`.
* Instead, infer what broader or related entities/concepts might provide the crucial missing information.
* For example, if `summary_1` describes a population for a small civil parish, but the question wants total population of the wider region, your `query` should target that wider region (e.g., "Madeira archipelago population in 2011").
* Similarly, if `summary_1` covers a song and the question wants the album it came from, but first hop got song-level documents, your query should retrieve documents about the album itself.
4. **How to Build the Query:**
* Identify the entities or topics mentioned in `summary_1` that appear related but different from first-hop documents.
* Reframe the query to explicitly mention these broader or related entities connected to the original question.
* Include relevant key context from the question to maintain specificity, but shift focus to the missing piece.
* The goal is to retrieve documents that link or complement what was retrieved initially.
5. **Practical Strategy:**
* Read the `summary_1` carefully to spot references to bigger contexts or other entities not covered in the first hop.
* Ask yourself, "What entity or aspect does this summary hint at that could answer the original question but was not found yet?"
* Formulate a precise, focused factual query targeting that entity or concept to retrieve the missing documents.
6. **Output:**
* Produce only the field `query` as a clear, concise question or keyword phrase designed for efficient retrieval of **second-hop documents**.
* Ensure the query relates logically to the original question while targeting the broader or complementary knowledge identified in `summary_1`.
* Do **not** include the original question or simply rephrase it.
* Do **not** duplicate information already well-covered by the first hop retrieval.
By following these principles, you will help the multi-hop retrieval system find all necessary documents to answer the multi-faceted original question completely.
[HotpotQA Prompt End][](https://raw.githubusercontent.com/gepa-ai/gepa/refs/heads/main/assets/aime_prompt.png)
Click to view full AIME prompt
[AIME Prompt Begin]
You will be given one math problem as plain text under a key like "problem." Your job is to solve it correctly and return:
* reasoning: a concise, logically ordered solution that uses identities/structure to avoid brute force, ends with a quick verification.
* answer: the final requested number/expression only (no extra words).
Formatting:
* Use exactly two top-level fields named "reasoning" and "answer."
* Keep reasoning succinct but complete. Bullet points are fine.
* The answer field must contain only the final value requested (e.g., 227, 585, 601).
General problem-solving guidance:
* Parse the problem type (e.g., base representation, intersecting families of subsets, avoiding arithmetic progressions, symmetric sums with constraints, ordered tuples counting).
* Always enforce domain constraints (e.g., base-b digits in 0..b−1; no leading zero for base-10 "three-digit"; ordered vs unordered families; strict increase conditions in sequences).
* Use algebraic identities and modular arithmetic to reduce the search space; prefer structural arguments over naive enumeration.
* For "greatest/least" questions, derive tight bounds and give a construction that attains them.
Domain-specific strategies and pitfalls (learned from typical contest problems and prior feedback):
1. Base-conversion/digit rearrangement:
* Translate positional notation correctly: in base b, (a b c)_b = a·b^2 + b·b + c; in base 10: abc = 100a + 10b + c.
* Enforce digit ranges strictly (e.g., in base 9, digits ∈ {0,…,8}; if also a is a base-10 leading digit, then a ∈ {1,…,8}).
* Set up equality and simplify. Use modular constraints to prune: • Mod 9 often collapses coefficients; e.g., 99a = 71b + 8c ⇒ mod 9 gives b + c ≡ 0 (mod 9). • Mod 8: 99 ≡ 3, 71 ≡ 7 ⇒ 3a ≡ 7b (mod 8) ⇒ b ≡ −3a (mod 8).
* Solve within digit bounds and verify numerically.
1. Palindromes across bases:
* Bound the base length by magnitude (e.g., n < 1000 ⇒ octal has 3–4 digits).
* Characterize palindromes: • 3-digit octal: (A B A)_8 = 65A + 8B. • 4-digit octal: (A B B A)_8 = 513A + 72B (with A ≥ 1).
* Enumerate small parameter ranges and test the other-base palindrome constraint. For "greatest", check candidates in descending order with justification.
1. Symmetric sums with a + b + c fixed (ordered triples of nonnegative integers):
* Use identities to compress expressions: S = ab(a + b) + bc(b + c) + ca(c + a) = (a + b + c)(ab + bc + ca) − 3abc.
* With a + b + c known (e.g., 300), convert the given sum into a relation among ab + bc + ca and abc.
* Use the shift a = A + x etc. to isolate a product like (a−A)(b−A)(c−A) and deduce factorization constraints, enabling clean counting.
* Count ordered solutions carefully; include/exclude symmetric/degenerate cases precisely.
1. Intersecting families of subsets (collections from the power set):
* Intersecting means every pair has nonempty intersection. The empty set cannot be included.
* Complement pairs: S and S^c cannot both be present. Use this to structure counts.
* Use size-based pigeonhole facts: In [n], any two subsets of size > n/2 must intersect. For n = 5, any two subsets of size ≥ 3 intersect; thus "all subsets of size ≥ 3" is an intersecting family (size 16).
* Do not assume that "stars" (all subsets containing a fixed element) are the only intersecting families of maximum size. For odd n, both the star and "all subsets of size > n/2" have size 2^{n−1}.
* When counting collections of a fixed size: • Consider the minimum set size N in the family and do casework on how many 2-element sets are included (for n=5), as these control which 3-sets must be excluded (complements). • Ensure completeness of cases and avoid double counting by parameterizing canonical patterns (e.g., how many 2-sets, how they overlap, whether they share a common element). • Remember order of subsets in a collection does not matter; count distinct families.
1. Avoiding 4-term arithmetic progressions in a strictly increasing sequence with fixed anchors:
* First bound the variable terms by strict increase (e.g., if fixed terms are 3,4,5,...,30,40,50 then 6 ≤ a < b ≤ 29).
* Pre-eliminate values that cause a 4-term AP with three fixed terms: • 3,4,5,a forbids a = 6. • b,30,40,50 forbids b = 20. • Similarly, a,30,40,50 forbids a = 20.
* Start with the count of pairs from allowed values and then subtract specific pairs that complete APs with two fixed endpoints: • 3,5,a,b ⇒ (a,b) = (7,9). • 3,a,b,30 ⇒ (a,b) = (12,21). • 4,a,b,40 ⇒ (a,b) = (16,28). • 5,a,b,50 ⇒ (a,b) = (20,35) but may be outside bounds or pre-excluded (e.g., 20 banned).
* Systematically check all endpoint combinations; use the fact that if endpoints differ by Δ, then Δ must be divisible by 3 for a 4-term AP, and solve for integer a,b within bounds.
* Avoid double subtraction; ensure monotonicity and domain constraints are respected.
1. Order statistics with sum and absolute-sum constraints (e.g., x_1 ≤ ... ≤ x_n, sum |x_i| = 1, sum x_i = 0):
* Total positive mass equals total negative mass: both = 1/2.
* For maximizing x_k (k near the top): if there are T largest terms from k to n (T = n − k + 1), then sum of these T terms ≥ T·x_k. Since the total positive mass ≤ 1/2, we get x_k ≤ (1/2)/T.
* For minimizing x_l (l near the bottom): if there are l smallest terms, sum of these l terms ≤ l·x_l. Since the total negative mass is −1/2, we get x_l ≥ (−1/2)/l.
* To attain these bounds, concentrate masses evenly on exactly those positions: set the smallest l terms equal to −1/(2l), the largest T terms equal to 1/(2T), and the middle to 0 (respecting monotonicity). Verify sums and absolute sums.
* Example: For n=100, maximize x_76 − x_16: T = 25 ⇒ x_76 ≤ 1/50; l = 16 ⇒ x_16 ≥ −1/32; construction with 16 negatives at −1/32, 59 zeros, 25 positives at 1/50 attains 1/50 − (−1/32) = 41/800.
Quality checks:
* Verify digit/base constraints and final equalities numerically if applicable.
* For extremal problems, provide both a tight bound and an explicit construction achieving it.
* For counting, explicitly handle ordered vs unordered, exclude impossible/duplicate cases, and check complements/forbidden pairs.
* For AP-avoidance, confirm integrality and bounds; ensure no missed endpoint combinations.
* For "greatest/least" questions, justify optimality structurally (e.g., convexity/majorization/pigeonhole).
Finally:
* Put the clean final numeric result in the "answer" field only.
[AIME Prompt End]
* * *
## When GEPA Shines
[](https://github.com/gepa-ai/gepa#when-gepa-shines)
* **Expensive rollouts** — Scientific simulations, complex agents with tool calls, slow compilation. GEPA needs 100–500 evals vs 10K+ for RL.
* **Scarce data** — Works with as few as 3 examples. No large training sets required.
* **API-only models** — No weights access needed. Optimize GPT-5, Claude, Gemini directly through their APIs.
* **Interpretability** — Human-readable optimization traces show _why_ each prompt changed.
* **Complements RL** — Use GEPA for rapid initial optimization, then apply RL/fine-tuning for additional gains ([BetterTogether](https://arxiv.org/abs/2407.10930)).
* * *
## Further Reading
[](https://github.com/gepa-ai/gepa#further-reading)
* **Paper:**[GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning (arXiv:2507.19457)](https://arxiv.org/abs/2507.19457)
* **Experiment reproduction artifact:**[GEPA Artifact Repository](https://github.com/gepa-ai/gepa-artifact)
* **Talk Slides**: [GEPA Talk Slides](https://docs.google.com/presentation/d/1vIauqn55WfdgJjwU0IDjvaqpv1QHhvhPaLAKdrCFAEg/edit?usp=sharing)
* **Blog Posts:**
* [optimize_anything: A Universal API for Optimizing any Text Parameter](https://gepa-ai.github.io/gepa/blog/2026/02/18/introducing-optimize-anything/)
* [Automatically Learning Skills for Coding Agents](https://gepa-ai.github.io/gepa/blog/2026/02/18/automatically-learning-skills-for-coding-agents/)
* **Tutorials & Examples:**
* [dspy.GEPA Tutorials, with executable notebooks](https://dspy.ai/tutorials/gepa_ai_program/) Step-by-step notebooks showing how to use GEPA for practical optimization tasks via DSPy, including math, structured data extraction for enterprise tasks and privacy conscious delegation task.
* [Video tutorial by @weaviate on using dspy.GEPA to optimize a listwise reranker](https://www.youtube.com/watch?v=H4o7h6ZbA4o)
* [Matei Zaharia - Reflective Optimization of Agents with GEPA and DSPy](https://www.youtube.com/watch?v=rrtxyZ4Vnv8)
* [Building and optimizing a multi-agent system for healthcare domain using DSPy+GEPA](https://kargarisaac.medium.com/building-and-optimizing-multi-agent-rag-systems-with-dspy-and-gepa-2b88b5838ce2)
* **Social and Discussion:**
* [X (formerly Twitter) Announcement Thread (Lakshya A Agrawal)](https://x.com/LakshyAAAgrawal/status/1949867947867984322)
* [GEPA covered by VentureBeat](https://venturebeat.com/ai/gepa-optimizes-llms-without-costly-reinforcement-learning)
* [GEPA's use by Databricks covered by VentureBeat](https://venturebeat.com/ai/the-usd100m-openai-partnership-is-nice-but-databricks-real-breakthrough)
* Stay up to date:
* [@LakshyAAAgrawal on X (Twitter)](https://x.com/LakshyAAAgrawal)
* [@lateinteraction on X (Twitter)](https://twitter.com/lateinteraction)
* Questions, Discussions?
* [Join our Discord for active discussion](https://discord.gg/WXFSeVGdbW)
* [Join our Slack](https://join.slack.com/t/gepa-ai/shared_invite/zt-3o352xhyf-QZDfwmMpiQjsvoSYo7M1_w)
* [Open a GitHub issue](https://github.com/gepa-ai/gepa/issues)
* **GEPA Integrations:** Want to use GEPA in other frameworks?
* [DSPy Adapter Code](https://github.com/stanfordnlp/dspy/tree/main/dspy/teleprompt/gepa/gepa_utils.py) (integrates GEPA with [DSPy](https://dspy.ai/)),
* [MLflow Prompt Optimization](https://mlflow.org/docs/latest/genai/prompt-registry/optimize-prompts/) - GEPA is integrated into MLflow's `mlflow.genai.optimize_prompts()` API for automatic prompt improvement using evaluation metrics and training data. Works with any agent framework and supports multi-prompt optimization.
* [Pydantic AI](https://pydantic.dev/articles/prompt-optimization-with-gepa) - Prompt optimization for Pydantic AI.
* [Comet ML Opik](https://www.comet.com/docs/opik/agent_optimization/algorithms/gepa_optimizer) - Core optimization algorithm in Opik Agent Optimizer.
* [OpenAI Cookbook](https://cookbook.openai.com/examples/partners/self_evolving_agents/autonomous_agent_retraining) - Self-evolving agents with GEPA.
* [HuggingFace Cookbook](https://huggingface.co/learn/cookbook/en/dspy_gepa) - Prompt optimization guide.
* [Google ADK](https://adk.dev/optimize/) - Built-in agent optimization in Google's Agent Development Kit. [Community tutorial](https://raphaelmansuy.github.io/adk_training/blog/gepa-optimization-tutorial/).
* [Contributed Adapters](https://github.com/gepa-ai/gepa/blob/main/src/gepa/adapters) – see our adapter templates and issue tracker to request new integrations.
* [DefaultAdapter](https://github.com/gepa-ai/gepa/blob/main/src/gepa/adapters/default_adapter) - System Prompt Optimization for a single-turn task.
* [ConfidenceAdapter](https://github.com/gepa-ai/gepa/blob/main/src/gepa/adapters/confidence_adapter) - Logprob-aware classification optimization using [`llm-structured-confidence`](https://github.com/rodolfonobrega/llm-structured-confidence). Detects lucky guesses by extracting token-level logprobs from structured JSON outputs with `enum` constraints, and feeds confidence diagnostics (logprob, probability, top alternatives) into the reflection LLM. Install with `pip install "gepa[confidence]"`. See the [guide](https://gepa-ai.github.io/gepa/guides/confidence-adapter/).
* [DSPy Full Program Adapter](https://github.com/gepa-ai/gepa/blob/main/src/gepa/adapters/dspy_full_program_adapter) - Evolves entire DSPy programs including signatures, modules, and control flow. Achieves **93% accuracy** on MATH benchmark (vs 67% with basic DSPy ChainOfThought).
* [Generic RAG Adapter](https://github.com/gepa-ai/gepa/blob/main/src/gepa/adapters/generic_rag_adapter) - Vector store-agnostic RAG optimization supporting ChromaDB, Weaviate, Qdrant, Pinecone, and more. Optimizes query reformulation, context synthesis, answer generation, and document reranking prompts.
* [MCP Adapter](https://github.com/gepa-ai/gepa/blob/main/src/gepa/adapters/mcp_adapter) - Optimize [Model Context Protocol (MCP)](https://modelcontextprotocol.io/) tool usage. Supports local stdio servers, remote SSE/HTTP servers, and optimizes tool descriptions and system prompts.
* [TerminalBench Adapter](https://github.com/gepa-ai/gepa/blob/main/src/gepa/adapters/terminal_bench_adapter) - Easily integrating GEPA into a Terminus, a sophisticated external agentic pipeline, and optimizing the agents' system prompt.
* [AnyMaths Adapter](https://github.com/gepa-ai/gepa/blob/main/src/gepa/adapters/anymaths_adapter) - Adapter for optimizing mathematical problem-solving and reasoning tasks. Contributed by [@egmaminta](https://github.com/gepa-ai/gepa/blob/main/www.linkedin.com/in/egmaminta).
* **GEPA uses**
* [Nous Research Hermes Agent: evolutionary self-improvement with DSPy + GEPA](https://github.com/NousResearch/hermes-agent-self-evolution)
* [Context Compression using GEPA](https://github.com/Laurian/context-compression-experiments-2508)
* [GEPA Integration into SuperOptiX-AI](https://github.com/SuperagenticAI/gepa-eval)
* [GEPA for Observable Javascript](https://observablehq.com/@tomlarkworthy/gepa)
* [bandit_dspy](https://github.com/evalops/bandit_dspy)
* [GEPA in Go Programming Language](https://github.com/XiaoConstantine/dspy-go)
* [100% accuracy using GEPA on the clock-hands problem](https://colab.research.google.com/drive/1W-XNxKL2CXFoUTwrL7GLCZ7J7uZgXsut?usp=sharing)
* [Prompt Optimization for Reliable Backdoor Detection in AI-Generated Code](https://www.lesswrong.com/posts/bALBxf3yGGx4bvvem/prompt-optimization-can-enable-ai-control-research)
* [Teaching LLMs to Diagnose Production Incidents with ATLAS+GEPA](https://www.arc.computer/blog/atlas-sre-diagnosis)
* [DataBricks: Building State-of-the-Art Enterprise Agents 90x Cheaper with GEPA](https://www.databricks.com/blog/building-state-art-enterprise-agents-90x-cheaper-automated-prompt-optimization)
* [comet-ml/opik adds support for GEPA](https://www.comet.com/docs/opik/agent_optimization/algorithms/gepa_optimizer)
* [Tuning small models (Gemma3-1B) for writing fiction](https://meandnotes.substack.com/p/i-taught-a-small-llm-to-write-fiction?triedRedirect=true)
* [Cut OCR Error Rates by upto 38% across model classes (Gemini 2.5 Pro, 2.5 Flash, 2.0 Flash)](https://www.intrinsic-labs.ai/research/ocr-gepa-v1.pdf)
* [Optimizing a Data Analysis coding agent with GEPA, using execution-guided feedback on real-world workloads](https://medium.com/firebird-technologies/context-engineering-improving-ai-coding-agents-using-dspy-gepa-df669c632766)
* [Generating Naruto (Anime) style dialogues with GPT-4o-mini using GEPA](https://zenn.dev/cybernetics/articles/39fb763aca746c)
* [Augmenting RL-tuned models with GEPA: Achieving +142% student performance improvement by augmenting a RL-tuned teacher with GEPA](https://www.arc.computer/blog/supercharging-rl-with-online-optimization)
* [DeepResearch Agent Optimized with GEPA](https://www.rajapatnaik.com/blog/2025/10/23/langgraph-dspy-gepa-researcher)
* Boosting Sanskrit QA: Finetuning EmbeddingGemma with 50k GEPA generated synthetic data samples [(Tweet)](https://x.com/dhrtha/status/1984315872547385504), [(Code)](https://github.com/ganarajpr/rgfe)
* [Simulating Realistic Market Research Focus Groups with GEPA-Optimized AI Personas](https://x.com/hammer_mt/status/1984269888979116061)
* [Google ADK: Official agent optimization powered by GEPA](https://adk.dev/optimize/)
* [HuggingFace Cookbook on prompt optimization for with DSPy and GEPA](https://huggingface.co/learn/cookbook/en/dspy_gepa)
* [OpenAI Cookbook showing how to build self-evolving agents using GEPA](https://cookbook.openai.com/examples/partners/self_evolving_agents/autonomous_agent_retraining)
* [What Do Prompts Reveal About Model Capabilities in Low-Resource Languages? (AfricaNLP 2026)](https://openreview.net/attachment?id=7JZmTp85Yf&name=pdf)
* [Beyond the Answer: Decoding the Behavior of LLMs as Scientific Reasoners (ICLR 2026 Workshop)](https://arxiv.org/abs/2603.28038)
* [Self-Optimizing Multi-Agent Systems for Deep Research (ECIR 2026 Workshop) — GEPA outperforms TextGrad and expert-crafted prompts](https://arxiv.org/abs/2604.02988)
* * *
## Contributions
[](https://github.com/gepa-ai/gepa#contributions)
We welcome adapters, bug fixes, and new use cases. See [src/gepa/adapters/](https://github.com/gepa-ai/gepa/blob/main/src/gepa/adapters) for adapter examples and the [contributing guide](https://gepa-ai.github.io/gepa/guides/contributing/).
**Want to highlight your use case?** Reach out to [lakshyaaagrawal@berkeley.edu](mailto:lakshyaaagrawal@berkeley.edu) or [submit via GitHub](https://github.com/gepa-ai/gepa/issues/new?title=Project%20Submission&body=Organization:%0A%0AProject%20Description:%0A%0AResults:%0A%0ALink%20to%20paper/blog/code:).
* * *
## Citation
[](https://github.com/gepa-ai/gepa#citation)
undefinedbibtex
@misc{agrawal2025gepareflectivepromptevolution,
title={GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning},
author={Lakshya A Agrawal and Shangyin Tan and Dilara Soylu and Noah Ziems and Rishi Khare and Krista Opsahl-Ong and Arnav Singhvi and Herumb Shandilya and Michael J Ryan and Meng Jiang and Christopher Potts and Koushik Sen and Alexandros G. Dimakis and Ion Stoica and Dan Klein and Matei Zaharia and Omar Khattab},
year={2025},
eprint={2507.19457},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2507.19457},
}
undefined
[](https://www.star-history.com/#gepa-ai/gepa&Date)
## About
Optimize prompts, code, and more with AI-powered Reflective Text Evolution
[gepa-ai.github.io/gepa/](https://gepa-ai.github.io/gepa/ "https://gepa-ai.github.io/gepa/")
### Resources
[Readme](https://github.com/gepa-ai/gepa#readme-ov-file)
### License
[MIT license](https://github.com/gepa-ai/gepa#MIT-1-ov-file)
### Contributing
[Contributing](https://github.com/gepa-ai/gepa#contributing-ov-file)
### Citation
Cite this repository
Loading
Something went wrong.
### Uh oh!
There was an error while loading. [Please reload this page](https://github.com/gepa-ai/gepa).
[Activity](https://github.com/gepa-ai/gepa/activity)
[Custom properties](https://github.com/gepa-ai/gepa/custom-properties)
### Stars
[**3.9k** stars](https://github.com/gepa-ai/gepa/stargazers)
### Watchers
[**15** watching](https://github.com/gepa-ai/gepa/watchers)
### Forks
[**333** forks](https://github.com/gepa-ai/gepa/forks)
[Report repository](https://github.com/contact/report-content?content_url=https%3A%2F%2Fgithub.com%2Fgepa-ai%2Fgepa&report=gepa-ai+%28user%29)
## [Releases 42](https://github.com/gepa-ai/gepa/releases)
[v0.1.1 Latest Mar 16, 2026](https://github.com/gepa-ai/gepa/releases/tag/v0.1.1)
[+ 41 releases](https://github.com/gepa-ai/gepa/releases)
## [Packages 0](https://github.com/orgs/gepa-ai/packages?repo_name=gepa)
No packages published
## [Used by 341](https://github.com/gepa-ai/gepa/network/dependents)
[*  *  *  *  *  *  *  *  + 333](https://github.com/gepa-ai/gepa/network/dependents)
## [Contributors 41](https://github.com/gepa-ai/gepa/graphs/contributors)
* [](https://github.com/LakshyAAAgrawal)
* [](https://github.com/gepa-bot)
* [](https://github.com/claude)
* [](https://github.com/Shashikant86)
* [](https://github.com/aria42)
* [](https://github.com/mwildehahn)
* [](https://github.com/apps/copilot-swe-agent)
* [](https://github.com/ShriyaaNarayanan)
* [](https://github.com/TomeHirata)
* [](https://github.com/apps/copilot-pull-request-reviewer)
* [](https://github.com/egmaminta)
* [](https://github.com/Shangyint)
* [](https://github.com/dbreunig)
* [](https://github.com/MatsErdkamp)
[+ 27 contributors](https://github.com/gepa-ai/gepa/graphs/contributors)
## Languages
* [Jupyter Notebook 70.7%](https://github.com/gepa-ai/gepa/search?l=jupyter-notebook)
* [Python 29.2%](https://github.com/gepa-ai/gepa/search?l=python)
* [HTML 0.1%](https://github.com/gepa-ai/gepa/search?l=html)
## Footer
[](https://github.com/) © 2026 GitHub,Inc.
### Footer navigation
* [Terms](https://docs.github.com/site-policy/github-terms/github-terms-of-service)
* [Privacy](https://docs.github.com/site-policy/privacy-policies/github-privacy-statement)
* [Security](https://github.com/security)
* [Status](https://www.githubstatus.com/)
* [Community](https://github.community/)
* [Docs](https://docs.github.com/)
* [Contact](https://support.github.com/?tags=dotcom-footer)
* Manage cookies
* Do not share my personal information
You can’t perform that action at this time.